
计算机组成与体系结构B卷(2011)最终版
计算机组成与体系结构B卷(2011)最终版
选择题
1. Interrupt system is implemented by:
A. only hardware
B. only software
C. both hardware and software
D. none of the above
Answer: C. both hardware and software
Explanation:
An interrupt system involves both hardware and software components. The
hardware part is responsible for detecting interrupts (e.g., via
interrupt controllers) and signaling to the CPU. The software part
handles interrupt service routines (ISRs), which are executed when an
interrupt occurs. So, both hardware and software are essential for
implementing an interrupt system.
2. In a ________ bus, all devices derive timing information from a common clock line.
A. system
B. asynchronous
C. internal
D. synchronous
Answer: D. synchronous
Explanation:
In a synchronous bus, all devices are synchronized to a
common clock, meaning the timing of data transfers is coordinated using
this clock. This ensures that the devices know when to send and receive
data in sync with the clock signal.
3. In carry-lookahead adder, the expression ________ is called the generate function $ G_i $ for stage i.
A. $ x_i + y_i $
B. $ x_i y_i $
C. $ x_i y_i $
D. $ x_i y_i c_i $
Answer: C. $ x_i y_i $
Explanation:
In a carry-lookahead adder (CLA), the generate function $ G_i $ is used
to determine whether a carry will be generated at the $ i $-th stage.
The generate function is $ G_i = x_i y_i $, which means a carry is
generated if both input bits at position $ i $ are 1. This is crucial
for speeding up the carry propagation in the adder.
4. ______ has/have internal fragmentation problem.
A. Paging
B. Segmentation with paging
C. Segmentation
D. Segmentation and segmentation with paging
Answer: A. Paging
Explanation:
In paging, memory is divided into fixed-size pages, and
if a process does not fully occupy the last page, the remaining space in
that page is wasted, leading to internal fragmentation.
In segmentation and segmentation with
paging, memory is divided based on logical segments, and there
is no fixed size like in paging, so internal fragmentation is typically
not a problem.
5. Assume that the capacity of a kind of SRAM chip is 32K×32, so the sum of address lines and data lines of this chip is ______.
A. 47
B. 64
C. 46
D. 74
Answer: A. 47
解释:
SRAM芯片的容量为 32K × 32,表示有 32K(即 32 × 1024 =
32768)个存储单元,每个单元存储 32 位数据。因此:
- 地址线的数量是 32768 的二进制表示需要 15 条地址线(因为 $ 32768 = 2^{15} $)。
- 数据线的数量是 32 条(每个单元存储 32 位数据)。
所以,总的地址线和数据线数量是 $ 15 + 32 = 47 $。
6. The time to complete a read or write operation on a disk can be divided into two parts: the seek time and the ________.
A. transfer time
B. access time
C. sector time
D. rotational delay time
Answer: D. rotational delay time
解释:
磁盘的读写操作时间通常分为两个部分:寻道时间(seek
time)和旋转延迟时间(rotational delay
time)。寻道时间是指磁头移动到正确位置的时间,而旋转延迟时间是指等待磁盘旋转到正确扇区所需的时间。
7. In DMA transfers, the data transfer unit between memory and I/O devices is ________.
A. byte
B. word
C. block of data
D. bit
Answer: C. block of data
解释:
在DMA(直接存储器访问)传输中,数据传输的单位通常是一个数据块(block of
data),而不是单个字节、字(word)或比特。DMA通过传输较大块的数据来减少CPU的干预,从而提高数据传输效率。
8. Microprogram sequencing can be implemented by ________.
A. PC
B. control store
C. μPC
D. SRAM
Answer: C. μPC
解释:
微程序序列通常通过微程序计数器(μPC)来实现。μPC是用来指示当前执行的微指令地址,它控制微程序的顺序执行。微程序存储器(control
store)存储微指令,μPC用于读取和执行这些微指令。
9. The 32-bit value 0x30a79847 is stored to the location 0x1000. If the system is little endian, the value of the byte ______ is stored in address 0x1002.
A. 0xa7
B. 0x47
C. 0x98
D. 0x30
Answer: A. 0xa7
解释:
在小端模式(Little Endian)下,数据是按字节反向存储的。32位数据
0x30a79847 在内存中的存储顺序是:
- 地址 0x1000 存储
0x47 - 地址 0x1001 存储
0x98 - 地址 0x1002 存储
0xa7 - 地址 0x1003 存储
0x30
因此,存储在地址 0x1002 的字节是 0xa7。
10. Which of the following is not the constituent of the I/O device’s interface circuit?
A. instruction register
B. data register
C. status register
D. address decoder
Answer: A. instruction register
解释:
I/O设备的接口电路通常包括:
- 数据寄存器(data register):用于存储数据的输入或输出。
- 状态寄存器(status register):用于存储设备的当前状态。
- 地址解码器(address decoder):用于选择特定的设备或寄存器。
指令寄存器(instruction register)通常与CPU的指令执行过程有关,而不是I/O设备的接口电路组成部分。
11. Which one of the following is not used to prevent data hazards?
A. Bypassing
B. Forwarding
C. Stall
D. Freeze or Flush
Answer: D. Freeze or Flush
解释:
数据危害是由于指令执行过程中对数据的依赖引起的问题。为了解决数据危害,通常采取以下方法:
- 绕过(Bypassing)和转发(Forwarding)用于在流水线中直接将数据从一个阶段传递到下一个阶段,从而避免等待。
- 停顿(Stall)是通过暂停流水线的一部分操作,来避免数据危害的发生。
Freeze 或 Flush 是指对流水线进行强制停止或清除的操作,通常不用于直接解决数据危害问题,而是用于其他控制流问题。
12. Addressing memory by giving a register (explicit or implicit) plus a ________ constant offset as effective address is called ________.
A. direct addressing
B. register addressing
C. indexed addressing
D. immediate addressing
Answer: C. indexed addressing
解释:
索引寻址(indexed
addressing)是一种寻址方式,其中内存地址通过给定寄存器值(显式或隐式)和一个常数偏移量来计算得到。在这种模式下,寄存器中的值和常数偏移量的和形成有效地址。
- 直接寻址(direct addressing)通常指的是直接给定一个地址作为操作数。
- 寄存器寻址(register addressing)是通过寄存器本身作为操作数来寻址。
- 立即寻址(immediate addressing)是直接使用一个常数作为操作数。
13. In IEEE 754 floating point number standard, instead of the signed exponent, E, the value actually stored in the exponent field is an unsigned integer ________.
A. $ E' = E + 255 $
B. $ E' = E + 127 $
C. $ E' = E + 256 $
D. $ E' = E + 128 $
Answer: B. $ E' = E + 127 $
解释:
在IEEE
754浮点数标准中,浮点数的指数部分是通过加上一个偏移值来存储的,称为偏移量(bias)。对于单精度浮点数(32位),该偏移量为127。也就是说,存储在指数字段中的值
$ E' $ 是指数 $ E $ 加上127,$ E' = E + 127
$。这使得指数能够表示正负值,从而更方便处理。
14. In a computer with a microprogrammable control unit the period of the clock is determined by ________.
A. the delay of the control memory.
B. the delay of the main memory.
C. the delay of the ALU.
D. the sum of two of the above delays.
Answer: D. the sum of two of the above delays.
- 微程序控制单元基础
- 微程序控制单元使用存储在控制存储器中的微指令来产生计算机操作所需的控制信号。
- 计算机的时钟周期(或循环时间)是指两个连续时钟脉冲之间的时间。它决定了计算机执行指令的速度。
- 对涉及组件的分析
- 控制存储器延迟
- 控制存储器存储微指令。访问这些微指令(从控制存储器中读取)所需的时间是一个重要因素。如果读取一条微指令需要一定的时间,那么这种延迟会影响整个时钟周期。
- 主存储器延迟
- 计算机经常需要从主存储器中访问数据。例如,当一条指令需要从主存储器中获取一个操作数时,访问该数据(读或写)的时间是决定整体延迟的一部分。在微程序控制单元中,主存储器访问时间会对决定时钟周期的总延迟产生影响。
- ALU(算术 - 逻辑单元)延迟
- ALU执行算术和逻辑运算。在执行指令的过程中,ALU操作的时间也会对整个指令执行时间产生影响,从而影响时钟周期。在很多情况下,时钟周期是由控制存储器延迟、主存储器延迟和ALU延迟中的两个或多个延迟之和来决定的。因为计算机操作通常涉及控制信号的获取(控制存储器)、数据的访问(主存储器)和运算(ALU)等步骤,这些操作的延迟共同作用,决定了计算机的基本操作节奏,也就是时钟周期。所以答案是D,即上述延迟中的两个延迟之和。
- 控制存储器延迟
15. In memory-mapped I/O system, we use ________ to differentiate memory locations and I/O devices.
A. different addresses
B. different address buses
C. different instructions
D. different control signals
Answer: A. different addresses
解释:
在内存映射I/O系统中,内存位置和I/O设备通过不同的地址来区分。内存和I/O设备共享相同的地址总线,但使用不同的地址范围来区分内存和I/O设备。这样,CPU可以通过读取或写入特定地址来访问内存或I/O设备。
简答题
在进位前瞻加法器中,每个比特切片需要使用输入 \(a_i\)、\(b_i\) 和 \(c_i\) 来产生生成函数 \(g_i\)、传播函数 \(p_i\) 和和输出 \(s_i\)。有一个提议,建议将标准的传播函数定义 \(p_i = a_i + b_i\) 替换为使用异或函数的版本:\(p_i = a_i \oplus b_i\)。进位函数仍按原来方式在进位前瞻单元中实现:\(c_{i+1} = g_i + p_i \cdot c_i\)。
(1) 修改后的传播函数是否能在进位前瞻单元中正确计算进位信号?为什么?
答案: 是的,修改后的传播函数可以正确计算进位信号。
解释: 新的传播函数定义为 \(p_i = a_i \oplus b_i\),与传统的 \(p_i = a_i + b_i\) 不同,主要区别在于使用了异或操作。异或函数 \(p_i = a_i \oplus b_i\) 只有当 \(a_i\) 和 \(b_i\) 中恰好有一个为 1 时才为 1,而当两者都为 1 或都为 0 时,\(p_i\) 都为 0。然而,当 \(a_i\) 和 \(b_i\) 都为 1 时,生成函数 \(g_i\) 会为 1,因此进位 \(c_{i+1}\) 会是 1,不受传播函数的变化影响。进位计算公式 \(c_{i+1} = g_i + p_i \cdot c_i\) 仍然能够正常工作。所以,修改后的传播函数并不会影响进位信号的正确计算。
(2) 使用异或版本的传播信号有什么优点?
答案: 使用异或版本的传播信号的优点是,它简化了和位 \(s_i\) 的计算。
解释: 在进位前瞻加法器中,和位 \(s_i\) 的计算公式为: $ s_i = a_i b_i c_i $ 传统加法器中,传播函数是 \(p_i = a_i + b_i\),这涉及到一个 OR 操作。而使用 \(p_i = a_i \oplus b_i\) 后,传播函数直接与和位的计算公式一致。这意味着传播函数的计算可以直接用来计算和位 \(s_i\),减少了需要计算的逻辑门数量。特别是在处理大规模加法器(例如 32 位或 64 位加法器)时,这种优化能显著减少硬件复杂度,从而提高计算效率。
总结:
问题 (1): 使用修改后的传播函数 \(p_i = a_i \oplus b_i\) 不会影响进位信号的正确计算,因为当 \(a_i\) 和 \(b_i\) 都为 1 时,生成函数 \(g_i\) 会确保进位为 1,进位计算公式仍然有效。
问题 (2): 使用异或版本的传播信号的好处是,传播信号和和位的计算可以共享相同的逻辑操作,这样可以减少硬件所需的逻辑门数量,尤其在大规模加法器中,能够优化计算过程并降低硬件复杂度。
在缓存存储系统中,写操作的写回(write-back)和写直达(write-through)有什么区别?
答案:
写直达(Write-through):
在写直达缓存系统中,当发生写操作时,缓存和主内存会同时更新。这确保了缓存和主内存的数据始终保持一致。然而,缺点是每次写操作都需要访问主内存,这可能会降低系统的性能,特别是当写操作频繁时。写回(Write-back):
在写回缓存系统中,只有缓存被更新,并且会设置一个“脏”位(modified bit)来标记缓存中的数据已经被修改。主内存只有在缓存块被替换(驱逐)时,才会更新。这个方法比写直达更快,因为它避免了频繁的主内存访问,并且当缓存块中有多个字被写入时,只需要一次主内存写操作。但它的缺点是主内存可能会变得不一致,并且需要额外的脏位来指示哪些缓存块已经被修改。
解释:
写直达(Write-through):
写直达的优点是缓存和主内存始终保持一致,但每次写操作都需要访问主内存,这会导致系统的性能下降。写回(Write-back):
写回的优点是减少了访问主内存的频率,提高了系统性能,尤其是在写操作较多的情况下。然而,主内存可能会变得不一致,并且需要额外的脏位来标记哪些缓存块已经修改过。
硬件控制与微程序控制的优缺点是什么?
答案:
- 硬件控制:
- 优点:
- 快速操作: 硬件控制单元通常速度较快,因为它们使用组合逻辑电路直接实现控制功能,从而加快指令执行速度。
- 缺点:
- 成本较高: 设计和实现硬件控制单元的成本较高,因为它们需要复杂的逻辑电路。
- 不灵活: 一旦需要修改或添加新功能,硬件控制单元就很难进行更改或扩展,需要重新设计和修改硬件。
- 设计和实现时间较长: 由于硬件的复杂性,设计和实现硬件控制系统的时间较长。
- 优点:
- 微程序控制:
- 优点:
- 低成本: 微程序控制单元通常设计和实现成本较低,因为它们使用存储器(如ROM或RAM)来存储微指令,设计复杂度较低。
- 高灵活性: 微程序控制单元具有较高的灵活性,修改或添加新功能只需更改存储器中的微指令,而无需重新设计硬件。
- 缺点:
- 操作较慢: 微程序控制单元的执行速度通常比硬件控制单元慢,因为它需要从存储器中提取和解码微指令,这会占用更多时间。
- 在高速系统中性能较差: 在高性能或高速计算机中,由于微程序控制的较慢速度,可能成为系统性能的瓶颈,降低整体性能。
- 优点:
总结:
- 硬件控制 速度快,但设计和实现成本高且不易修改。
- 微程序控制 成本低且灵活,适合修改,但速度较慢,可能在高性能系统中成为瓶颈。
子程序和中断服务程序有什么区别?
答案:
子程序:
子程序是由程序指令调用的一段代码,用于执行调用程序所需要的特定任务或功能。它是程序正常流程的一部分,由程序显式地调用来处理某个特定功能。中断服务程序(ISR):
中断服务程序是一种特殊的函数,它是由中断事件自动触发的,通常由输入操作、硬件错误或其他外部事件触发。ISR独立于当前正在执行的程序,它执行的功能可能与当时执行的程序无关。因此,中断服务程序必须设计成不会影响或改变当前程序的数据或状态信息。
解释:
- 子程序 是程序的一部分,调用时由程序显式指定,通常用于执行需要重复调用的任务。
- 中断服务程序 是响应中断事件自动执行的代码,执行时与当前运行的程序无关,必须确保不会干扰当前程序的正常执行。
使用顺序乘法算法,执行 A×B 运算,其中 A = 1011 和 B = 1101。写出计算过程。
答案:

问题:
- 假设计算机的指令长度是 8 位。设计人员需要 3 条指令,每条指令有两个 3 位操作数;2 条指令,每条指令有一个 4 位操作数;4 条指令,每条指令有一个 3 位操作数。如何设计指令格式?
解决方案:
1 | 00 aaa bbb |
问题:
设计一个逻辑电路,用于实现一个优先级网络。该网络处理三个中断请求线(INTR1、INTR2、INTR3)。当接收到来自某个线上的请求时,网络会在相应的确认线(INTA1、INTA2、INTA3)上生成一个确认信号。如果接收到多个请求,只有优先级最高的请求会被确认。优先级的顺序是:INTR1 > INTR2 > INTR3。
任务:
- 给出INTR1、INTR2、INTR3的真值表,求得各输出INTA1、INTA2、INTA3的真值表。
- 给出INTA1、INTA2、INTA3的逻辑表达式,并给出实现该优先级网络的逻辑电路。
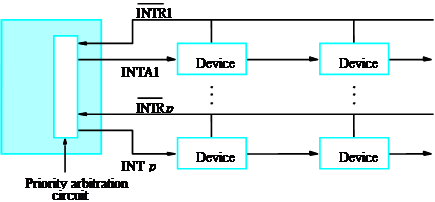
解答:
(1) 真值表:
| INTR1 | INTR2 | INTR3 | INTA1 | INTA2 | INTA3 |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0 | 1 |
| 0 | 1 | 0 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 1 | 0 |
| 1 | 0 | 0 | 1 | 0 | 0 |
| 1 | 0 | 1 | 1 | 0 | 0 |
| 1 | 1 | 0 | 1 | 0 | 0 |
| 1 | 1 | 1 | 1 | 0 | 0 |
(2) 逻辑表达式和电路设计:

根据真值表,我们可以得出以下逻辑表达式:
- INTA1(确认 INTR1):
- 只有当 INTR1 = 1 时,INTA1 才为 1,且 INTR2 和 INTR3 可以是任意值。所以: $ = $
- INTA2(确认 INTR2):
- 当 INTR1 = 0 且 INTR2 = 1 时,INTA2 为 1,且 INTR3 可以是任意值。所以: $ = $ 这里 \(\overline{\text{INTR1}}\) 表示 INTR1 为 0。
- INTA3(确认 INTR3):
- 当 INTR1 = 0 且 INTR2 = 0 且 INTR3 = 1 时,INTA3 为 1。所以: $ = $
逻辑电路设计:
为了实现这个优先级网络,我们可以根据以上的逻辑表达式设计电路。
- INTA1:直接由 INTR1 控制。
- 连接一个输入线 INTR1,输出 INT1。
- INTA2:由 INTR1 和 INTR2 控制,使用与非门实现。
- 输入 INTR1 和 INTR2,通过与非门得到 \(\overline{\text{INTR1}}\) 和 \(\text{INTR2}\),然后连接到与门得到 INTA2。
- INTA3:由 INTR1、INTR2 和 INTR3 控制。
- 输入 INTR1、INTR2 和 INTR3,使用与非门和与门组合实现。
具体电路实现中,您将需要三个与门和一些反相器(NOT门)来根据上述的逻辑表达式连接输入和输出。
总结:
- 真值表:列出 INTR1、INTR2、INTR3 对应的 INTA1、INTA2 和 INTA3 的值。
- 逻辑表达式:根据真值表推导出每个输出的逻辑表达式。
- 电路设计:使用与门、或门和非门实现上述逻辑表达式。
这样的设计可以实现一个基于优先级的中断确认网络,确保优先级最高的中断请求得到确认。





