
计算机组成原理总复习
计算机组成原理总复习
这是一个对于所有知识点的一个简要的回顾,打算明确了究竟哪些是考点之后,重新看一遍书,看一遍PPT,把计算机组成原理这门课彻底学通透。
😎那么开始吧,只需要打这一次,之后就完全轻松了,何乐而不为?
Chapter 1 Basic Structure of Computers
这一小节的重点在于知道五个基本功能单元,知道对应的功能,其他知识作为了解即可。
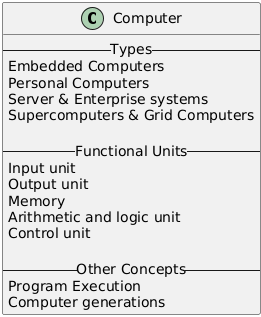
一、计算机类型(Computer Types)
- 嵌入式计算机(Embedded Computers)
- :嵌入式计算机是一种专门设计用于嵌入到其他设备或系统中的计算机。它们通常被集成到各种电子设备中,如汽车的电子控制系统、工业自动化设备、智能家居设备等。这些计算机的主要功能是执行特定的、预先编程的任务,以支持其所嵌入设备的主要功能。例如,在汽车中,嵌入式计算机可以控制发动机的燃油喷射、安全气囊的触发等。
- 个人计算机(Personal Computers)
- :个人计算机是为个人使用而设计的计算机。它包括台式机、笔记本电脑和平板电脑等多种形式。用户可以使用个人计算机进行各种任务,如文字处理、浏览网页、玩游戏、多媒体制作等。例如,人们可以在台式机上使用Microsoft Word编写文档,在笔记本电脑上通过浏览器访问在线学习课程,或者在平板电脑上观看视频。
- 服务器和企业系统(Server & Enterprise systems)
- :服务器是一种为网络中的其他计算机(客户端)提供服务的计算机。企业系统则是由多个服务器和相关软件组成的复杂系统,用于支持企业的各种业务流程。服务器可以提供文件存储、打印服务、数据库管理等功能。例如,企业的邮件服务器负责收发和存储员工的电子邮件,数据库服务器用于存储和管理企业的业务数据,如客户信息、订单记录等。
- 超级计算机和网格计算机(Supercomputers & Grid
Computers)
- :超级计算机是一种具有极高性能的计算机,它能够进行非常复杂和大规模的计算任务。超级计算机主要用于科学研究(如气象预报、天体物理模拟)、工程设计(如飞机设计、芯片设计)等领域。网格计算机则是通过网络将多个计算机资源连接起来,形成一个计算网格,以协同完成复杂的计算任务。例如,在气候模拟研究中,超级计算机可以处理大量的气象数据,预测气候变化;网格计算机可以利用分布在不同地点的计算机资源,共同处理大型的数据分析任务。
二、计算机的五个基本功能单元(Five Basic Functional Units of Computers)
- 输入单元(Input Unit)
- :输入单元是计算机接收外部信息的部分。它可以接收多种形式的输入,如键盘输入的字符、鼠标的移动和点击信号、扫描仪输入的图像、麦克风输入的音频等。这些输入数据被转换为计算机能够理解的二进制代码,然后传送到计算机的其他部分进行处理。例如,当用户在键盘上按下字母“A”时,键盘将这个按键信号转换为对应的二进制代码,通过输入接口传送给计算机的内部电路。
- 输出单元(Output Unit)
- :输出单元是计算机将处理结果以人们能够理解的形式输出的部分。常见的输出设备包括显示器、打印机、扬声器等。例如,计算机可以将处理后的文字、图像等信息通过显示器显示出来,让用户看到;也可以将文档内容通过打印机打印在纸张上;还可以将音频信号通过扬声器播放出来。
- 存储器(Memory)
- :存储器是计算机存储数据和程序的地方。它分为主存储器(内存)和辅助存储器(外存)。主存储器用于暂时存储正在运行的程序和数据,其特点是读写速度快,但存储容量相对较小。辅助存储器用于长期存储大量的数据和程序,如硬盘、U盘等,其存储容量大,但读写速度相对较慢。例如,当计算机运行一个文字处理软件时,软件程序和正在编辑的文档内容会被加载到内存中,方便CPU快速访问;而用户长期保存的文档、软件安装包等则存储在硬盘等外存设备中。
- 算术逻辑单元(Arithmetic and Logic Unit)
- :算术逻辑单元(ALU)是计算机的核心部件之一,主要负责执行算术运算(如加、减、乘、除)和逻辑运算(如与、或、非)。在计算机执行程序的过程中,ALU根据控制单元的指令对从存储器中读取的数据进行运算。例如,在计算两个数字的和时,ALU会将这两个数字从存储器中取出,进行加法运算,并将结果返回给存储器或输出单元。
- 控制单元(Control Unit)
- :控制单元是计算机的指挥中心,它协调和控制计算机各个部件的工作。控制单元从存储器中读取指令,对指令进行译码,然后根据译码结果向计算机的其他部件(如输入单元、输出单元、算术逻辑单元、存储器)发送控制信号,以确保各个部件按照正确的顺序和方式协同工作。例如,在执行一个简单的加法程序时,控制单元会先从存储器中读取加法指令,然后指挥算术逻辑单元执行加法运算,并将结果存储到指定的存储单元中。
三、程序执行(Program Execution)
- :程序执行是计算机运行软件的过程。当一个程序被启动时,它的指令和相关数据首先被从存储设备(如硬盘)加载到内存中。然后,控制单元按照程序中的指令顺序,一条一条地读取并执行指令。在执行指令的过程中,可能会涉及到数据的读取、运算、存储和输出等操作。例如,当运行一个简单的计算器程序时,用户输入数字和运算符号,程序将这些输入数据存储在内存中,然后控制单元指挥算术逻辑单元进行相应的运算,最后将结果输出到显示器上。
四、计算机代(Computer Generations)
- :计算机代是根据计算机技术的主要发展阶段来划分的。第一代计算机使用电子管作为主要的电子元件,体积庞大、能耗高、运算速度慢,主要用于科学计算。第二代计算机以晶体管取代电子管,体积减小、能耗降低、运算速度有所提高,并且开始应用于数据处理等领域。第三代计算机采用集成电路,性能进一步提升,可靠性增强,软件也得到了进一步发展。第四代计算机使用大规模和超大规模集成电路,计算机的性能、存储容量、可靠性等方面都有了巨大的进步,计算机的应用范围也更加广泛,包括个人计算机的普及等。
Chapter 9 Arithmetic
这一章应该会考察的比较套路,注意各种套路题目的原理即可。
我自己的话,对于恢复除法,不恢复除法和浮点数的截断,运算还不够清楚,待会就要去进修一下这两块。
整数表示(Integer Representation)
三种整数的表示,注意各种表示方法的范围,同时注意补码进行加减法的时候是直接进行的,不需要特别麻烦的操作。
注意源码和补码对于0的表示都有两种。
有符号整数(Signed integer)
其符号部分是 1 位的值,正数时该位为 0,负数时该位为 1。以下是几种有符号整数的表示方法:
1. 原码(signed magnitude)
- 定义:用最高位表示符号(0 表示正,1 表示负),其余位表示数值的绝对值。
- 举例:比如对于 8 位二进制表示,+5 的原码是 00000101,-5 的原码就是 10000101。
- 特点:
- 简单直观,能直接看出数值的正负和绝对值大小。
- 进行加减法运算时相对复杂,因为要先判断符号,再根据符号决定是做加法还是减法操作,而且还涉及到符号位的处理等情况。
2. 反码(1’s complement)
- 定义:正数的反码与原码相同;负数的反码是在原码的基础上,除符号位外,其余各位按位取反。
- 举例:同样以 8 位二进制为例,+5 的反码是 00000101(与原码相同),-5 的原码是 10000101,那么 -5 的反码就是 11111010。
- 特点:
- 可以通过对反码进行加法运算来实现减法(将减法转化为加法),但运算过程中可能会出现循环进位等较复杂的情况需要额外处理。
3. 补码(2’s complement)
- 定义:正数的补码与原码相同;负数的补码是其反码加 1。
- 举例:还是 8 位二进制的情况,+5 的补码是 00000101,-5 的原码为 10000101,反码是 11111010,那么 -5 的补码就是 11111010 + 1 = 11111011。
- 特点:
- 补码在计算机中应用广泛,因为它可以方便地实现加减法统一运算,即计算机中只要用加法器就能完成加减法运算,通过对补码进行加法操作,按照自然的二进制加法规则进行运算,结果就是正确的(包含符号的)运算结果,极大地简化了硬件电路设计。
- 补码的表示范围是不对称的,例如对于 8 位有符号整数补码表示,范围是 -128 到 +127。
有符号数加减法规则(补码形式,2’s complement form)
1. 加法(Addition)
- 规则阐述: 将参与运算的两个数的 n 位补码表示形式直接相加,把符号位当作最高有效位(MSB,Most Significant Bit)来参与运算,并且忽略从最高有效位产生的进位信号(carry out signal)。
- 示例说明: 假设使用 8
位补码来表示有符号数,进行加法运算,例如计算 3 + 5:
- 首先,3 的 8 位补码表示为 00000011,5 的 8 位补码表示为 00000101。
- 然后按照规则将它们直接相加:
1 | 00000011 |
得到的结果 00001000 对应的十进制数就是 8,这就是正确的加法运算结果,这里最高有效位没有产生进位,即便产生了进位按照规则也是要忽略的。
再比如计算 -3 + 5: - -3 的 8 位补码为 11111101(先求原码 10000011,再求反码 11111100,最后加 1 得到补码 11111101),5 的 8 位补码为 00000101。 - 进行相加:
1 | 11111101 |
得到的结果 00000010 对应的十进制数是 2,也是符合 -3 + 5 的正确结果,同样忽略最高位可能产生的进位情况。
2. 减法(Subtraction)
- 规则阐述: 若要执行 X - Y 的运算,需要先求出 Y 的补码(如果 Y 本身是补码形式则直接使用),然后按照加法规则(上述的规则①),将 Y 的补码与 X 的补码相加即可。
- 示例说明: 例如计算 5 - 3:
- 先求 -3 的补码(前面已求出为 11111101),5 的补码是 00000101。
- 接着将它们相加:
1 | 00000101 |
得到的结果 00000010 对应的十进制数为 2,这与 5 - 3 的结果相符。
再比如计算 3 - 5: - 先求 -5 的补码,5 的原码是 00000101,反码是 11111010,补码就是 11111011。 - 然后 3 的补码 00000011 与 -5 的补码 11111011 相加:
1 | 00000011 |
得到的结果 11111110 对应的十进制数是 -2,这也符合 3 - 5 的实际运算结果。
利用补码进行有符号数的加减法运算,通过这样统一的规则,计算机硬件可以使用较为简单的加法器电路就能够高效、准确地完成各种加减法运算,大大简化了运算逻辑和硬件实现成本。
算术溢出(补码形式,Arithmetic overflow (2 ’s-complement form))
对于溢出判断的条件必须掌握,两个符号相同的最后的结果的符号却发生了改变,说明发生了溢出。
- 定义与判断规则: 在补码形式下进行加法运算时,如果参与相加的两个数符号相同(同为正数或同为负数),那么当且仅当运算结果的符号与这两个相加数的符号相反时,就发生了算术溢出。
- 示例解释:
- 正数相加溢出情况: 例如,使用 8 位补码表示数字,我们要计算 127 + 1。127 的 8 位补码是 01111111,1 的 8 位补码是 00000001。按照补码加法规则相加:
1 | 01111111 |
这里两个加数都是正数(符号位为 0),但相加结果 10000000 的符号位变成了 1(表示负数),这就发生了溢出。因为在 8 位补码能表示的正数范围是 0 到 +127,这个结果超出了该范围,所以出现溢出且符合判断规则。 - 负数相加溢出情况: 再比如计算 -128 + (-1),-128 的 8 位补码是 10000000,-1 的 8 位补码是 11111111。相加如下:
1 | 10000000 |
两个加数都是负数(符号位为 1),可结果 01111111 的符号位变为 0(表示正数),同样发生了溢出。因为 8 位补码能表示的负数范围是 -128 到 -1,这个运算结果超出了范围,符合溢出的判断规则。
加法器(Adder)
① 1 - 位全加器(1-bit Full-adder)
注意区分
s和c,s是本位,通过两个异或门即可得到。c是进位,通过三个与门和两个或门即可得到,这是一个十分普通的元器件。
- 逻辑表达式与功能: 全加器有三个输入,分别是本位的两个加数 \(x_i\)、\(y_i\) 以及来自低位的进位 \(c_i\),有两个输出,分别是本位和 \(s_i\) 以及向高位的进位 \(c_{i + 1}\)。 其逻辑表达式如下:
- 作用与意义: 1 位全加器是构建多位加法器的基础部件,它能够完成一位二进制数的全加运算(包含考虑低位进位的情况),多个 1 位全加器可以级联起来构成多位的加法器,从而实现对多位二进制数的加法运算。
② n - 位行波进位加法器(n - bit ripple - carry Adder)
注意判断进位的两种方式,尤其是第二种,可能会比较陌生,是通过两个进位的异或是否为1来进行判断的。
- 构成与工作原理: n 位行波进位加法器是由 n 个 1 位全加器级联组成的。最低位的全加器的进位输入 \(c_0\) 一般初始设为 0(因为没有更低位向它进位了),然后每个全加器的进位输出连接到下一位全加器的进位输入,依次类推,就像波浪一样逐位传递进位信号,从而实现对 n 位二进制数的加法运算。
先行进位加法器(Carry-lookahead addition)
1. 基本运算表达式回顾
在介绍先行进位加法器的相关特殊函数之前,先回顾一下之前提到的本位和 \(s_i\) 以及向高位进位 \(c_{i + 1}\) 的基本表达式:
本位和 \(s_i\) 表达式: \(s_i = x_i \oplus y_i \oplus c_i\) 这里 \(x_i\) 和 \(y_i\) 是本位的两个加数,\(c_i\) 是来自低位的进位,通过异或运算来确定本位相加的结果。
向高位进位 \(c_{i + 1}\) 表达式: \(c_{i + 1} = x_i y_i + x_i c_i + y_i c_i\) 它体现了根据本位两个加数以及低位进位的情况,来决定是否向高位产生进位,是后续推导先行进位相关函数的基础。
2. 生成函数(Generate function) \(G_i\)
定义与表达式: \(G_i = x_i y_i\) 它被称为第 \(i\) 级的生成函数。从表达式可以看出,当本位的两个加数 \(x_i\) 和 \(y_i\) 都为 \(1\) 时,不管低位是否有进位(\(c_i\) 的情况),都会向高位产生进位,也就是“生成”了进位,所以用 \(x_i y_i\) 来定义这个函数,用于判断本位是否必然会产生进位的情况。
意义与作用: 在先行进位加法器的设计和分析中,生成函数 \(G_i\) 是一个很关键的概念。它可以帮助提前确定在哪些位必然会产生进位,以便更快地计算出各个位的进位情况,而不用像行波进位加法器那样逐位等待进位传递,从而提高加法运算的速度。例如,在多位加法运算中,如果某一位的 \(G_i\) 为 \(1\),那就意味着该位一定会向高位进位,后续的进位计算可以基于这个已知条件进行优化处理。
3. 传播函数(Propagate function) \(P_i\)
定义与表达式: \(P_i = x_i + y_i\) 它是第 \(i\) 级的传播函数。从逻辑上来说,当 \(x_i\) 或者 \(y_i\) 为 \(1\) 时,若低位有进位(\(c_i\) 为 \(1\)),那么这个进位就会通过本位“传播”到高位,所以用 \(x_i + y_i\) 来定义这个函数,用于判断本位是否能将低位的进位传播到高位去。
意义与作用: 传播函数 \(P_i\) 同样对先行进位加法器的高效运作起着重要作用。它可以帮助确定进位在各个位之间传播的可能性,与生成函数配合使用,能够提前计算出多位加法运算中每一位的进位情况。比如,当 \(P_i\) 为 \(1\) 且低位有进位时,就可以知道这个进位会通过本位继续往高位传播,这样在设计电路或者进行逻辑分析时,可以更迅速准确地把握进位的传递路径和最终结果,实现快速的加法运算,减少因逐位等待进位传递所耗费的时间,提升运算效率。
顺序乘法(正乘法,Sequential multiplication (Positive Multiplication))
注意这里讲解的是将乘数左移,教材和PPT使用的是右移,心里知道会用就可以了。考试可能会考这方面的题,这里简单的说明一下步骤:先写上被乘数,然后一开始有一个C,被乘数下方是0,乘数直接放在0的后面。
之后就是一个又一个的过程,如果乘数的最后一位是1,那么
Add,否则Noadd,之后整体右移shift,乘数有多少位,这个周期就进行多少次。
- 原理与过程: 顺序乘法主要用于两个正数相乘,通常采用类似于手工乘法的竖式计算方式在二进制下进行运算。将乘数和被乘数都用二进制表示,从乘数的最低位开始,依次检查每一位的值。如果该位为 1,则把被乘数对应左移相应的位数后,与之前的部分积相加(初始部分积为 0);如果该位为 0,则什么都不做,只将被乘数左移,然后继续检查下一位乘数,如此循环,直到乘数的所有位都处理完毕,最终得到的结果就是两数相乘的积。
- 示例: 例如计算二进制数 101(十进制的 5)和
110(十进制的 6)相乘。
- 初始部分积为 00000。
- 乘数 110 的最低位是 0,此时只将被乘数 101 左移一位变为 1010。
- 接着检查乘数的次低位 1,把当前左移后的被乘数 1010 与部分积相加(此时部分积仍为 00000),得到新的部分积 1010。
- 再检查乘数的最高位 1,将当前被乘数再左移一位变为 10100,然后与部分积 1010 相加,得到最终结果 11110(十进制为 30),也就是 5×6 的正确乘积。
- 特点: 这种方法直观易懂,逻辑简单,但对于位数较多的二进制数相乘,运算步骤会比较繁琐,运算速度相对较慢。
布斯算法(有符号操作数乘法,Booth algorithm (Signed operand Multiplication))
提高效率,将乘数转换了一下,其他的和之前的顺序乘法都是一样的。
到现在遇到过一道题,就是问通过这个算法, 最后乘法的次数变为了多少次,因此一定要掌握Booth对于乘数的改变。
- 原理与目的: 布斯算法主要用于有符号数的乘法运算,目的是提高乘法运算效率并且能正确处理符号位。它基于对乘数二进制位的一种特殊扫描和操作方式,通过判断相邻两位乘数的变化情况来决定是进行加法、减法还是移位操作,巧妙地将有符号数乘法转化为一系列有规律的运算步骤,避免了像普通顺序乘法那样复杂的符号处理和重复的加法操作。
- 运算步骤:
- 首先,在乘数的最低位后面添加一个辅助位 0,然后从最低位开始,依次检查相邻的两位(当前位和更高一位)。
- 如果这两位是 01,则把被乘数加到部分积上;如果是 10,则把被乘数的补码加到部分积上;如果是 00 或 11,则部分积保持不变,之后都要对部分积和乘数进行右移一位的操作,重复这个过程,直到处理完所有位(包含添加的辅助位)。
- 最后得到的部分积就是有符号数相乘的结果,符号位也会自动正确处理在结果之中。
- 示例: 假设有符号数 -3(补码表示为 11111101)和
5(补码表示为 00000101)相乘。
- 对乘数 00000101 添加辅助位 0 变为 000001010,部分积初始为 000000000。
- 从最低位开始检查,相邻两位为 10,将被乘数 -3 的补码 11111101 加到部分积上,得到部分积 111111010,然后右移一位变为 111111101。
- 继续检查下一组相邻位为 01,把被乘数 5 的补码(就是其原码 00000101)加到部分积上,得到 000000110,再右移一位变为 000000011。
- 如此继续操作,最终得到的结果就是两数相乘的积(补码形式),转换为十进制能得到正确的有符号乘积结果。
- 优势: 相较于普通的有符号数乘法方法,布斯算法减少了加法操作的次数,尤其在乘数中连续出现多个 0 或 1 的情况下优势更明显,能有效提高乘法运算的速度,并且保证了有符号数乘法结果的正确性,在计算机的乘法运算实现中有广泛应用。
不恢复除法(Non restoring division)
不恢复除法,如果减去之后变为负数之后,会不断的加,因此称作不恢复除法。
- 原理与特点: 不恢复除法是一种用于二进制除法运算的算法,它与传统的恢复余数除法有所不同。在运算过程中,当出现余数不够减除数的情况时,并不像恢复余数除法那样立即恢复余数,而是继续按照特定的规则进行下一步运算,通过后续的操作来纠正余数和商的值,这样可以简化运算步骤,减少硬件实现的复杂性,提高除法运算的效率。
- 运算步骤:
- 首先将被除数放在余数寄存器中,除数放在除数寄存器中,商寄存器初始为全 0。
- 然后根据余数的正负来决定下一步操作:如果余数为正,则将余数左移一位,商寄存器对应位置 1,再用新余数减去除数;如果余数为负,则将余数左移一位,商寄存器对应位置 0,然后把除数加到余数上(相当于纠正之前不够减的情况)。
- 重复这个过程,直到达到规定的运算次数(比如被除数和除数的位数决定的次数等),最终商寄存器中的值就是商,余数寄存器中的值就是余数。
浮点数(Floating point numbers)
这个一定会考的,掌握单精度和双精度的位数,和三部分的含义。
中间的指数位数,实际书写的时候是要减去的。
如果进行加减法运算的时候,注意是要进行对齐操作的。
① IEEE 754 标准:单精度格式、双精度格式(IEEE 754 standard: Single precision format, Double precision format)
- IEEE 754 标准概述: IEEE 754 是电气和电子工程师协会(IEEE)制定的用于表示浮点数的标准,它规定了浮点数在计算机中的具体格式以及相应的运算规则等,旨在确保不同计算机系统在处理浮点数时能够有统一、准确的表示和运算方式,提高了浮点数运算的兼容性和可移植性。
- 单精度格式(Single precision format):
- 单精度浮点数采用 32 位二进制来表示,其中包含 1 位符号位(S),用来表示浮点数的正负,0 表示正数,1 表示负数;8 位指数位(E),采用偏移码(移码)表示,其偏移量通常为 127,通过指数位可以确定浮点数的量级;23 位尾数位(M),表示浮点数的有效数字部分,但实际上隐含了最高位的 1(规格化表示时),通过这三部分共同组成一个单精度浮点数,能够表示一定范围和精度的实数。
- 例如,一个单精度浮点数的二进制表示为 0 10000001 10100000000000000000000,根据 IEEE 754 标准,符号位 0 表示正数,指数位 10000001(十进制为 129)减去偏移量 127 得到实际指数为 2,尾数位结合隐含的最高位 1 表示的有效数字为 1.101(二进制),换算成十进制后可以得到对应的实数数值。
- 双精度格式(Double precision format):
- 双精度浮点数使用 48 位二进制表示,由 1 位符号位(S)、11 位指数位(E)(偏移量通常为 1023)和 52 位尾数位(M)组成。相比单精度,双精度能表示更大范围和更高精度的实数,适用于对数值精度要求更高的科学计算等场景。
- 同样,通过各部分按照相应规则解析,就能从二进制表示还原出对应的实数数值,例如一个双精度浮点数的二进制表示按位解析后可以得到其具体的符号、指数以及有效数字,进而确定它所代表的实数。
- 意义与应用: IEEE 754 标准的单精度和双精度格式在计算机的数值计算、图形处理、科学模拟等众多领域广泛应用,它们在满足不同精度需求的同时,使得浮点数在不同的计算机平台上能够保持一致的表示和运算行为,方便了程序的开发和数据的交互。
② 浮点数的算术运算(Arithmetic Operations On Floating point Numbers)
- 加法和减法(Addition and Subtraction):
- 步骤与原理: 首先要对参与运算的两个浮点数进行对阶操作,也就是将两个数的指数部分调整为相同的值,这通常是通过将指数小的那个数的尾数进行右移(同时指数相应增加)来实现,使得它们的阶码一致,便于后续的尾数相加或相减操作;然后进行尾数的加法或减法运算,根据符号位判断是做加法还是减法;最后对结果进行规格化处理,若得到的尾数不符合规格化要求(比如最高位不是 1 等情况),则要进行相应的调整(如左移尾数同时减小指数等),并处理好可能出现的溢出等特殊情况,得到最终的运算结果。
- 示例: 假设要计算两个单精度浮点数的加法,比如浮点数 A 的二进制表示对应十进制数值为 3.5,浮点数 B 的二进制表示对应十进制数值为 2.5,按照上述步骤,先对阶、再尾数相加、最后规格化等操作,最终得到两数相加后的浮点数结果(同样以 IEEE 754 标准的单精度格式表示),其对应的十进制数值就是 6.0,实现了浮点数的加法运算。
- 乘法和除法(Multiplication and Division):
Chapter 8 The Memory System
1. 基本概念(Basic Concepts)
这里的核心概念是大端模式和小端模式,几乎一定会考一道选择题,注意小端模式是最右边的在最低的地址,大端相反。
除此之外,要求区分三种访问方式,哪些存储设备是顺序访问,直接访问,随机访问。
并且区分易失性和可擦除性。
① 字(Word)
- 定义:固定大小的一组比特被称作一个字。例如,在计算机存储中,可能将 16 位或者 32 位等特定长度的二进制信息划分为一个单元,这个单元就是字。它是计算机存储和处理数据时的一个基本逻辑单位,不同的计算机系统或者应用场景下,字所包含的比特数可能有所不同。
② 字长(word length)
- 定义:每个字中所包含的比特数量就被称为字长。字长体现了计算机一次能够处理的数据规模大小,是衡量计算机性能的一个重要指标。比如常见的 8 位字长意味着计算机一次处理 8 个比特的数据,而 32 位字长的计算机一次能处理 32 个比特的数据,字长越长,通常计算机的数据处理能力越强,可表示的数据范围也越广,能够更高效地执行复杂运算等任务。
③ 存储器地址(memory address)
- 定义与作用:地址是用于标识存储器中存储位置的编号。就如同现实生活中每家每户都有一个具体的门牌号一样,在计算机的存储器中,每个存储单元(可以存储一个字或者一个字节等)都被分配了唯一的地址,通过这个地址,计算机的处理器等部件就能准确地找到并访问相应存储位置的数据,方便进行数据的读写操作,是实现数据存储和检索的关键要素。
④ 大端序(big endian)
- 原理与特点:在大端序存储方式中,字中更重要的字节(也就是最左边的字节)会被存放在较低的字节地址中。例如,对于一个 32 位(4 字节)的数据 0x12345678,如果采用大端序存储,在存储器中从低地址到高地址存放的字节依次为 0x12、0x34、0x56、0x78,这种存储顺序符合人们常规从高位到低位书写和理解数字的习惯,常用于一些网络协议等对数据顺序有特定要求的场景,便于对数据进行统一的解读和处理。
⑤ 小端序(little endian)
- 原理与特点:与大端序相反,小端序是将字中相对不重要的字节(即最右边的字节)存放在较低的字节地址中。还是以 32 位数据 0x12345678 为例,若采用小端序存储,在存储器中从低地址到高地址存放的字节依次为 0x78、0x56、0x64、0x12。小端序在某些处理器架构中应用较多,它在进行数据的存储和读取时,与处理器的内部运算逻辑等结合起来,可能会更方便一些,例如在一些以字节为基础进行数据处理的运算中,按照小端序存储能更快地获取到数据的低位部分用于计算等。
⑥ 访问方法(accessing method)
- 顺序访问(Sequential Access):
- 原理与特点:顺序访问是按照数据存储的先后顺序依次进行访问的方式。就好比我们听磁带音乐一样,只能按照磁带录制的顺序一首一首地听下去,不能随意跳到指定的某一首歌曲。在存储系统中,顺序访问通常适用于磁带、磁盘等存储介质,数据是一个接一个依次存放的,要访问某个特定位置的数据,往往需要先顺序读取前面的数据,读写速度相对较慢,不过它的存储结构相对简单,成本也较低,常用于对读写速度要求不高、数据量较大且有顺序性的数据存储场景,比如档案资料的长期存档等。
- 直接访问(Direct Access):
- 原理与特点:直接访问允许直接定位到指定存储位置去访问数据,不需要像顺序访问那样依次遍历前面的数据。比如磁盘中的磁道和扇区结构,通过知道相应的磁道号、扇区号等信息,磁盘驱动器就能快速定位到对应的存储区域读取或写入数据。这种访问方式比顺序访问速度快,在需要快速获取特定数据的应用场景中比较适用,不过其存储设备的结构相对复杂一些,成本也会高一点,常用于数据库等需要频繁随机查找特定记录的系统中。
- 随机访问(Random Access):
- 原理与特点:随机访问能够在几乎相同的时间内访问存储器中的任意存储单元,不受数据存储顺序的限制。例如计算机的内存(随机存取存储器,RAM)就是典型的随机访问存储设备,处理器可以随时根据给定的地址快速地读写内存中的任意位置的数据,这使得计算机能够高效地执行各种复杂的程序和运算,因为可以快速获取到所需的数据进行处理,不过随机访问存储器通常成本较高,并且在断电后数据容易丢失(针对一些常见的易失性随机访问存储器而言)。
⑦ 易失性/非易失性、可擦除/不可擦除(volatile/nonvolatile, erasable/nonerasable)
- 易失性(volatile)与非易失性(nonvolatile):
- 易失性:易失性存储设备在断电后其存储的数据会丢失,例如随机存取存储器(RAM),计算机运行时,内存中存放着正在处理的程序和数据,但一旦突然断电,内存中的这些信息就不复存在了,需要重新启动计算机并加载相关程序等才能继续工作。它的优点是读写速度快,能快速配合计算机处理器进行实时的数据交互和运算,常用于计算机的主存储器等对读写速度要求高的场景。
- 非易失性:非易失性存储设备在断电后数据仍然能够保存,像硬盘、固态硬盘(SSD)以及只读存储器(ROM)等都属于非易失性存储介质。硬盘可以长期存储大量的数据,即使电脑关机,下次开机依然可以从中读取之前保存的数据,这使得它成为计算机系统用于长期存储文件、操作系统等重要数据的关键部件;只读存储器(ROM)中的数据在出厂时就被固化,一般不能随意修改,常用于存储计算机的基本启动程序等固定不变的信息,保障计算机能够正常开机启动等基础功能。
- 可擦除(erasable)与不可擦除(nonerasable):
- 可擦除:可擦除的存储设备允许用户或者系统对存储的数据进行擦除操作,然后重新写入新的数据,例如闪存(常见于U盘、固态硬盘等)就是可擦除的存储介质,用户可以方便地删除 U 盘中不需要的文件,再存入新的文件。这种特性使得存储设备可以被重复利用,灵活地更新存储内容,适应不同的使用需求。
- 不可擦除:不可擦除的存储介质一旦数据写入后就很难或者几乎不能进行修改和擦除操作,像一些只读存储器(ROM)中的特定部分,其数据是固化的,用于保证系统的稳定性和一些关键功能的永久性实现,防止误操作或者恶意篡改等情况影响系统的正常运行,不过随着技术发展,现在完全不可擦除的存储应用场景相对较少了,更多的是在一些特定的、对数据稳定性要求极高的安全关键系统中有一定应用。
2. 静态随机存取存储器(SRAM)芯片的内部结构(Internal organization of static RAM chips (16×8, 1K×1))
注意第一个是字,第二个是位,因此就有了字扩展和位扩展这两种扩展,一般考试的话,只能考画图以及个数的计算了,如果是字扩展的话,就是并行的, 会横着放,如果是位扩展的话,那么会竖着放,注意需要译码器,各种线的连接也需要注意。
- 16×8结构:
- 含义与布局:“16×8”表示该 SRAM 芯片有 16 个存储单元,每个存储单元能够存储 8 位数据(也就是一个字节)。从内部结构来看,它通常会有地址译码器,用于将外部输入的地址信号进行译码,从而准确选中对应的 16 个存储单元之一;还有存储矩阵,由多个存储单元组成,按照一定的行列排列方式布局,方便寻址和数据读写;同时具备读写控制电路,根据外部传来的读写控制信号,对选中的存储单元进行数据的读出或者写入操作。
- 示例与应用场景:这种结构的 SRAM 芯片适用于一些对读写速度要求较高、存储容量需求相对不大的场景,比如在某些小型的嵌入式系统中,用于暂存关键的控制参数、中间计算结果等,像智能仪表内部用于快速记录和读取实时监测数据的缓存部分就可能采用类似结构的 SRAM 芯片。
- 1K×1结构:
- 含义与布局:“1K×1”意味着芯片内有 1024(1K = 2¹⁰)个存储单元,且每个存储单元只能存储 1 位数据。其内部同样包含地址译码器来处理输入地址以选中具体存储单元,存储矩阵组织众多的单个位存储单元,读写控制电路保障数据的正常读写。不过由于每个单元只存 1 位,在实际应用中往往需要组合多个这样的芯片来构成可以存储字节或者多字节的数据存储模块,比如可以通过 8 片 1K×1 的 SRAM 芯片并联来实现 1K×8 的存储容量,从而方便与外部 8 位数据总线等进行适配和数据交互。
- 示例与应用场景:常用于构建更大型存储系统的基础单元,或者在一些对数据位操作较为精细、需要灵活组合存储位的特定电路设计中,例如在早期一些简单的数字逻辑电路实验平台中,用它来搭建自定义存储容量和存储格式的存储模块,方便学生学习和实践存储相关的原理和操作。
3. 异步动态随机存取存储器(DRAM)芯片的内部结构(Internal Organization of an Asynchronous DRAM Chip (2M×8))
注意与SRAM的区别,它有行地址选通和列地址选通。
- 含义与特点:“2M×8”表示此 DRAM 芯片内部包含 2×2²⁰ 个存储单元,每个存储单元可存储 8 位数据(一个字节)。与 SRAM 相比,DRAM 的内部结构更为复杂一些。它有行地址选通(RAS)和列地址选通(CAS)等控制信号相关的电路,因为 DRAM 对地址是分两次(先送行地址,再送列地址)来进行译码从而选中具体存储单元的,这样做是为了减少芯片引脚数量等,但也使得访问时序相对复杂,属于异步控制方式,即读写操作不像 SRAM 那样能快速响应,而是需要按照特定的时序信号要求来完成,所以称为异步 DRAM。
- 存储单元与刷新机制:DRAM 存储单元基于电容来存储电荷以表示数据信息(电容充电表示 1,放电表示 0),但电容存在漏电问题,会导致数据丢失,所以需要定期进行刷新操作,通过芯片内部的刷新电路按照一定的周期(通常是几毫秒)对所有存储单元进行重读和重写,以维持数据的正确性。其内部的存储矩阵也是按照行列方式排列,配合地址译码、读写控制等电路实现数据的存储和访问,常用于计算机的主存储器等大容量存储场景,尽管读写速度比 SRAM 慢,但成本低、集成度高,可以在满足一定性能需求的同时实现较大的存储容量,满足计算机系统对大量程序和数据的存储需求。
4. 存储器延迟(Memory Latency)、存储器带宽(Memory Bandwidth)
- 存储器延迟(Memory Latency):
- 定义与影响因素:存储器延迟指的是从处理器发出对存储器的访问请求开始,到数据真正被读取或写入完成所经历的时间间隔。它包含多个部分,比如地址译码时间、存储介质的访问时间(例如 DRAM 的行选通、列选通以及数据读出时间等)、数据传输时间等。不同类型的存储器有着不同的延迟特性,例如 SRAM 的延迟通常较短,因为其内部结构和读写机制使得它能较快响应访问请求,而 DRAM 由于存在复杂的地址译码、刷新等操作,延迟相对较长。存储器延迟会直接影响计算机系统的整体性能,较长的延迟意味着处理器在等待数据的时间增加,可能导致程序执行效率下降。
- 示例:在运行一个复杂的数据库查询操作时,如果存储器延迟过高,处理器需要长时间等待从内存中读取相关的数据记录,那么整个查询的响应时间就会变长,用户体验变差,所以在高性能计算机系统设计中,降低存储器延迟是一个重要的优化目标。
- 存储器带宽(Memory Bandwidth):
- 定义与计算方式:存储器带宽是指单位时间内存储器能够传输的数据量,通常用每秒传输的字节数(B/s)或者位(bit/s)来表示。其计算公式大致为:带宽 = 数据传输频率 × 每次传输的数据宽度(位宽)。例如,某内存的工作频率为 1000MHz,数据总线宽度为 64 位,那么它的带宽就是 1000MHz × 64bit = 64000Mbit/s = 8000MB/s(换算成字节每秒)。存储器带宽体现了存储器的数据传输能力,对于需要大量、快速传输数据的应用场景(如高清视频处理、大型游戏运行等)至关重要,较高的带宽能保证数据及时、顺畅地在处理器和存储器之间流动,满足系统的运算和处理需求。
- 优化与应用场景:为了提高存储器带宽,一方面可以提高存储器的工作频率,另一方面可以增加数据总线的宽度等。在现代计算机系统中,采用多通道内存技术(如双通道、四通道等)就是通过增加并行的数据传输通路来提升总的存储器带宽,从而提升系统的整体性能,像专业的图形处理工作站在处理大规模图形数据时,就依赖高带宽的内存来保证图形渲染等操作的高效进行。
5. 用小的存储器芯片构成大的存储器(Use small memory chips to constitute large memory (draw the figure))
这里的考点,大题一定会考一道芯片的扩展,因为不简单也不难,很符号华工的考试。
- 原理与方法:通常采用芯片扩展的方式来实现,常见的有位扩展、字扩展以及字位扩展。
- 位扩展:当需要增加存储单元存储数据的位数时采用位扩展方式。比如现有 1K×1 的芯片,要组成 1K×8 的存储器,就可以将 8 片 1K×1 的芯片并行连接,它们的地址线、控制线(如读写控制信号等)都分别并联在一起,而数据线分别对应字节的不同位(一片对应一位),这样就实现了存储位数从 1 位扩展到 8 位,使得存储单元能够存储一个完整的字节。
- 字扩展:若要增加存储单元的数量(即存储字数),则采用字扩展方法。例如用 1K×8 的芯片组成 4K×8 的存储器,需要 4 片芯片,将芯片的数据线都对应连接,读写控制信号也相连,但是地址线要通过译码器进行扩展,使得不同的地址范围能够选中不同的芯片,从而增加了总的存储单元数量,实现存储字数的扩展。
- 字位扩展:实际应用中更多是字位同时需要扩展的情况,比如从 1K×1 的芯片构建 4K×8 的存储器,就需要综合运用上述两种扩展方法,先通过位扩展将芯片组成合适的位宽,再通过字扩展增加存储单元数量,最终构成满足需求的大容量存储器。
- 示意图绘制(示例,以简单字扩展为例):
- 假设有两片 2K×8 的存储器芯片,要扩展成 4K×8 的存储器。首先画两条并行的横线代表地址总线(A0 - An,n 根据地址位数确定),两条竖线代表数据总线(D0 - D7),再画一条线代表读写控制信号(WR)。然后将两片芯片的数据线 D0 - D7 分别对应连接到总的数据总线 D0 - D7 上,读写控制信号 WR 也并联在一起。对于地址总线,通过一个 2 - 1 地址译码器(比如可以用简单的逻辑门电路实现),译码器的输入接高位地址位(比如 A11 等,取决于具体地址范围划分),输出分别连接到两片芯片的片选信号(CS),当 A11 为 0 时选中一片芯片,A11 为 1 时选中另一片芯片,这样就实现了字扩展,通过不同的地址范围可以访问两片芯片中的存储单元,从而构成了更大容量的存储器。(这里可根据具体需求进一步完善和细化图形,更准确地展示电路连接和扩展原理)
6. 存储器层次结构(Memory hierarchy)
这里不知道会不会考察简答题,就是说要构建出速度快容量大成本低的存储器是不可能的。
- 概念与构成:存储器层次结构是为了在性能和成本之间取得平衡,将不同类型、不同性能特点的存储器按照一定的层次组织起来的体系。一般由寄存器、高速缓存(Cache)、主存储器(如 DRAM)以及辅助存储器(如硬盘、固态硬盘等)构成,自上而下,速度越来越慢,容量越来越大,成本也越来越低。寄存器位于处理器内部,速度极快但容量很小,用于暂存正在处理的指令和数据;高速缓存处于寄存器和主存储器之间,速度比主存储器快,用于缓存主存中近期可能被频繁访问的数据和指令,减少处理器访问主存的等待时间;主存储器容量较大,用于存放运行的程序和数据;辅助存储器则用于长期存储大量的数据、文件以及操作系统等,虽然读写速度慢,但能提供海量的存储容量。
- 工作原理与优势:基于程序运行的局部性原理(后面会详细介绍),在程序执行过程中,往往对数据和指令的访问具有时间上和空间上的局部性特点,利用这一特性,通过把经常访问的数据和指令放在更靠近处理器、速度更快的存储层次中,如放在高速缓存里,当处理器再次需要时就能快速获取,避免每次都从低速的主存甚至更慢的辅助存储器中查找,从而提高整个计算机系统的平均访问速度,同时兼顾了大容量存储和低成本的需求,优化了系统的性能和成本效益比。
7. 高速缓存(Cache)的原理(Principle of cache)——局部性原理(Locality of reference: Temporal Locality, Spatial Locality)
这里有两个局部性。
- 时间局部性(Temporal Locality):
- 定义与解释:时间局部性是指程序中的某条指令或者某个数据一旦被访问,在不久的将来很可能会再次被访问。例如在一个循环结构中,循环体内的指令会被反复执行,每次循环都会访问这些指令,它们在时间上呈现出重复访问的特点;或者一个变量在程序的某个阶段被频繁读写,在后续较短时间内依然有较大概率继续被操作,这体现了指令和数据在时间维度上的局部性特征,也是高速缓存能够发挥作用的重要依据之一,因为可以把这些近期被频繁访问的内容放入高速缓存,下次访问时就能快速从缓存中获取,减少访问主存的时间延迟。
- 示例:在计算数组元素之和的程序中,循环遍历数组的代码段会多次被执行,每次循环都会访问数组的下标计算、元素读取等相关指令,这些指令就具有很强的时间局部性,将它们缓存起来能显著提高程序执行效率。
- 空间局部性(Spatial Locality):
- 定义与解释:空间局部性指的是程序访问了某个存储单元后,在不久的将来很可能会访问与其相邻的存储单元。比如在顺序访问数组元素时,当访问了数组中的一个元素后,下一次大概率会访问数组中的下一个相邻元素;或者在执行程序代码时,顺序执行的指令通常在存储器中也是相邻存储的,访问了一条指令后,接下来往往会访问其后面相邻的指令,这种在空间上呈现出的访问关联性就是空间局部性。基于此特性,高速缓存不仅可以缓存被访问的单个数据或指令,还可以缓存其相邻部分,进一步提高缓存的命中率,更好地发挥缓存对提高系统访问速度的作用。
- 示例:在读取文本文件内容的程序中,按顺序逐行读取文件内容时,每读取一行内容涉及的存储单元在存储器中是相邻的,这些相邻存储单元的内容就具有空间局部性,若将这部分内容放入高速缓存,后续读取就会更快捷,减少对主存的频繁访问。
8. 高速缓存的映射函数(Mapping functions of cache)
这个是必考考点,必须透彻。结合三种缓存的映射方式,结合三种替换算法, 和分页之类的进行考察。
- 直接映射(Direct mapping):
- 原理与方法:直接映射是一种简单的 Cache 与主存数据映射方式。它将主存按照 Cache 的大小进行分区,每个主存块只能映射到 Cache 中的一个特定位置,计算公式通常为:Cache 块地址 = 主存块地址 % Cache 总块数。例如,若 Cache 有 8 块,主存某块地址为 10,通过计算 10 % 8 = 2,那么该主存块就只能映射到 Cache 的第 2 块位置上。当处理器需要访问主存数据时,根据这个映射关系到对应的 Cache 块中查找,如果命中则直接从 Cache 获取数据,若未命中则需要从主存中读取数据并替换 Cache 中对应的块内容。
- 特点与优缺点:这种映射方式实现简单,硬件成本较低,但是容易出现 Cache 块冲突的情况,即不同的主存块可能会争用同一个 Cache 块位置,导致 Cache 命中率可能相对较低,不过在一些对成本敏感、对性能要求不是特别高的简单系统中仍有应用。
- 全相联映射(Fully associative mapping):
- 原理与方法:全相联映射允许主存中的任意一块都能映射到 Cache 中的任意一块位置上,没有固定的映射规则限制。当处理器要访问主存数据时,需要在整个 Cache 中进行查找,看是否有对应的主存块已经被缓存,通过比较主存块的标记(通常包含主存块地址等信息)和 Cache 中各块的标记来确定是否命中。
- 特点与优缺点:它的优点是能最大程度地利用 Cache 空间,减少块冲突,提高 Cache 命中率,因为主存块的映射选择非常灵活;缺点是硬件实现复杂,需要比较器等复杂电路来对所有 Cache 块进行标记比较,成本较高,查找速度也相对较慢,所以一般用于对性能要求极高、对成本不太敏感的高端系统中,比如一些高性能的服务器处理器中的部分缓存设计。
- 组相联映射(Set associative mapping):
- 原理与方法:组相联映射是介于直接映射和全相联映射之间的一种方式。它先将 Cache 分成若干组,然后主存块按照一定规则映射到这些组中,在组内则是全相联映射的方式,即主存块可以映射到组内的任意一块位置上。例如,将 Cache 分成 4 组,每组 2 块(这就是 2 - 路组相联),主存块先根据一定算法确定要映射到哪一组,然后在该组内的两块中查找是否命中。通常用公式计算主存块映射的组号,比如根据主存块地址的部分位来确定组号等。
- 特点与优缺点:组相联映射结合了直接映射实现相对简单和全相联映射命中率高的优点,在一定程度上降低了硬件成本,同时又能提高 Cache 命中率,减少块冲突的影响,在现代计算机系统的高速缓存设计中应用较为广泛,能在性能和成本之间取得较好的平衡。
9. 替换算法(Replacement Algorithm)
- 作用与重要性:在高速缓存中,当新的数据需要被缓存但 Cache 空间已满时,就需要采用替换算法来决定替换掉哪些已缓存的数据,以便腾出空间存放新数据。替换算法的优劣直接影响 Cache 的命中率,进而影响整个计算机系统的性能,选择合适的替换算法能让 Cache 更高效地缓存最有可能被再次访问的数据,减少从主存重新读取数据的次数。
- 常见替换算法:
- 先进先出(FIFO)算法:按照数据进入 Cache 的先后顺序进行替换,最先进入 Cache 的数据块会被最先替换掉。这种算法实现简单,但没有考虑数据的实际访问情况,可能会把后续仍有可能频繁访问的数据替换出去,导致 Cache 命中率不高,不过在一些简单、对性能要求不高的系统中可以使用。
- 最近最少使用(LRU)算法:它基于时间局部性原理,认为最近一段时间内最少被访问的数据块在未来短期内被访问的可能性也最小,所以当需要替换时,选择最近最少使用的数据块进行替换。LRU 算法相对更符合程序运行的实际访问规律,能有效提高 Cache 命中率,但硬件实现成本较高,需要额外的电路或软件机制来记录数据块的访问时间顺序等信息,常用于对性能要求较高的计算机系统中,如高性能的个人电脑、服务器等。
- 随机替换算法:顾名思义,就是随机选择 Cache 中的一个数据块进行替换,不考虑数据的进入顺序和访问频率等因素。这种算法实现简单,但效果往往不如 LRU 等基于访问规律的算法好,不过在一些特殊场景下,当硬件资源有限或者对 Cache 命中率要求不是特别精准时也有一定应用。
10. 写策略(Write policy)
很有可能会考察简答题,如果是写回的话,就是等到这个脏数据块要被替换出去的时候菜写进去主存,好处是速度快,坏处是可能导致数据丢失不一致,并且需要额外的内存存储脏位。写直达的话,好处是数据的一致性,能够保证获得到的数据一定是准确的,坏处自然是速度慢。
- 写回(Write back):
- 原理与操作方式:在写回策略下,当 CPU 对高速缓存(Cache)中的数据进行写操作时,并不会立即将数据写回主存,而是只更新 Cache 中的相应数据块,并将该数据块标记为“脏”(dirty)状态,表示其内容已经被修改但还未同步到主存。只有当这个“脏”数据块要被替换出 Cache 时(例如由于 Cache 已满,需要腾出空间给新的数据块等情况),才会把它写回主存对应的位置。这样做的好处是减少了不必要的主存写入操作,因为如果在 Cache 中的数据后续又被多次修改,按照写回策略就不用每次修改都去更新主存,从而提高了写操作的效率,尤其在频繁对同一数据进行写操作的场景中优势明显。
- 优缺点:优点是能够减少对主存的写操作次数,提升系统整体性能,特别是对于那些写操作频繁且数据在一段时间内主要在 Cache 中被反复修改的情况,能有效避免频繁写入主存带来的时间开销;缺点是增加了 Cache 管理的复杂性,需要额外的机制来记录数据块的“脏”状态,并且在系统出现故障(如突然断电等情况)时,如果“脏”数据块还没来得及写回主存,可能会导致数据丢失或不一致的问题,所以通常需要配合相应的硬件保护措施(如备用电源等)来保障数据的安全性。
- 写直达(Write through):
- 原理与操作方式:写直达策略要求 CPU 对 Cache 中的数据进行写操作时,同时要将数据立即写回主存对应的位置,保证 Cache 和主存中的数据始终保持一致。也就是说,每一次写操作都会直接穿透 Cache 层,同步更新主存内容,这样在任何时刻,主存的数据都是最新的,其他设备(如其他处理器核等,如果存在的话)访问主存时获取到的都是已更新的数据。
- 优缺点:优点是数据一致性维护简单,不需要复杂的“脏”数据块管理机制,主存中的数据始终能反映最新的写操作结果,对于多处理器系统或者有其他设备共享主存数据的场景,能有效避免数据不一致带来的问题;缺点是每次写操作都要涉及主存写入,会增加写操作的时间开销,尤其在频繁写操作的情况下,可能会成为系统性能的瓶颈,因为主存的访问速度相对较慢,过多的主存写入操作会拖慢整个系统的运行速度。
12. 虚拟内存原理(Principle of virtual memory)
- 概念与目的:虚拟内存是一种计算机系统内存管理技术,它为每个程序提供了一个比实际物理内存大得多的虚拟地址空间,使得程序在运行时仿佛拥有了足够多的内存来存放其所有的数据和指令,而实际上这些数据和指令并不一定都同时存放在物理内存中。其主要目的是解决物理内存容量有限的问题,让多个大型程序可以同时运行在有限的物理内存上,并且能够方便地进行内存管理,提高内存的利用效率,同时增强系统的安全性和稳定性。
- 工作机制:
- 地址转换:通过硬件(如内存管理单元,MMU)和软件(操作系统的内存管理模块)配合,将程序使用的虚拟地址转换为实际的物理地址。程序在编写和编译时都是基于虚拟地址空间进行操作的,当程序运行并访问某个虚拟地址时,MMU 会根据一定的映射规则(后面介绍的分页、分段等机制)查找对应的物理地址,然后到物理内存中去获取相应的数据或指令。
- 页面置换:由于虚拟地址空间通常远大于物理内存空间,不可能把所有虚拟内存对应的内容都装入物理内存,所以当物理内存已满且程序又需要调入新的数据或指令时,就需要采用页面置换算法(类似高速缓存中的替换算法),从物理内存中选择一些暂时不用或者近期使用频率较低的页面(内存管理的基本单位,通常是固定大小的一块内存区域)置换出去,腾出空间给新的页面,将需要的数据或指令从磁盘等辅助存储器(虚拟内存的后备存储设备)调入物理内存,以保证程序的继续运行,这个过程对程序是透明的,程序本身并不知道数据是在物理内存还是在磁盘上,只要虚拟地址能正确映射到有效的物理地址即可。
- 内存保护:虚拟内存还能实现内存保护功能,不同的程序在虚拟地址空间中有各自独立的区域,操作系统通过设置相应的访问权限(如可读、可写、可执行等),可以防止程序之间非法访问对方的内存区域,避免因一个程序的错误操作而影响其他程序的正常运行,提高了系统的稳定性和安全性。
13. 分页(虚拟地址到物理地址,Paging (Virtual Address to Physical address))
- 分页机制概述:分页是实现虚拟内存地址转换的一种常用方式,它将虚拟内存空间和物理内存空间都划分成固定大小的页面(page),通常页面大小在不同系统中可能有所不同(常见的有 4KB、8KB 等)。每个页面都有一个唯一的编号(页号),在进行地址转换时,虚拟地址由两部分组成,即页号和页内偏移量;同样,物理地址也由对应的物理页号和页内偏移量构成。通过某种映射关系(一般由页表来记录),可以根据虚拟地址中的页号查找出对应的物理页号,再结合原来的页内偏移量,就能得到最终的物理地址。
- 页表(Page table):
- 作用与结构:页表是用于记录虚拟页号和物理页号映射关系的表格,是实现虚拟地址到物理地址转换的核心数据结构。操作系统为每个进程维护一个页表,页表中的每一项(页表项)对应着一个虚拟页,记录了该虚拟页对应的物理页号以及一些其他相关的控制信息(如访问权限、是否在物理内存中(存在位)等)。当 CPU 需要访问虚拟地址对应的内存内容时,先从虚拟地址中提取出页号,然后通过查询页表找到对应的物理页号,再与虚拟地址中的页内偏移量组合形成物理地址,进而访问物理内存中的相应数据。
- 页表大小与存储问题:随着虚拟地址空间的增大和页面数量的增多,页表本身可能会占用大量的内存空间,而且每次地址转换都要查询页表,若页表过大,查询效率也会受到影响。为了解决这些问题,通常会采用多级页表、快表(TLB,后面介绍)等优化措施。多级页表将页表进行分层组织,只有在需要访问某一层的页表项时才将其调入内存,减少了不必要的内存占用;快表则是一种高速缓存,用于缓存近期经常访问的页表项,提高地址转换的速度,减少查询页表的时间开销。
- 地址转换过程示例: 假设页面大小为 4KB(即 2¹² 字节),虚拟地址为 32 位,那么虚拟地址的高 20 位表示页号,低 12 位表示页内偏移量。当 CPU 要访问一个虚拟地址对应的内存内容时,首先提取出虚拟地址中的页号部分,然后在页表中查找对应的物理页号(假设页表项中已经记录了正确的映射关系且该页面在物理内存中),得到物理页号后,再与虚拟地址中的页内偏移量组合,比如虚拟地址的页内偏移量是 0x100,物理页号对应的物理页面起始地址是 0x10000,那么最终的物理地址就是 0x10100(0x10000 + 0x100),通过这个物理地址就能访问到物理内存中对应的内容。
14. 磁性硬盘(Magnetic Hard Disk)
- 扇区、磁道、圆柱面(Sector, track, cylinder):
- 扇区(Sector):扇区是磁盘存储数据的基本单位,它是磁盘表面上被划分出来的一个个小区域,每个扇区通常可以存储固定大小的数据(常见的有 512 字节等)。就如同将一个圆形的蛋糕切成许多小块一样,磁盘的每个盘面都被划分成众多的扇区,数据是以扇区为单元进行读写的,读写头在定位到具体的扇区位置后才能进行相应的数据操作,扇区的编号一般从磁盘的最外圈开始顺序向内排列。
- 磁道(Track):磁道是磁盘盘面上一组同心圆的轨迹,每个盘面都有许多磁道,磁道的半径从磁盘的最外圈逐渐向内圈减小。数据是沿着磁道进行存储的,一个磁道可以包含多个扇区,例如一个磁道可能包含 64 个扇区等,不同磁道上的扇区数量可能相同(取决于磁盘的格式化设置等因素),读写头在不同磁道之间移动来访问不同位置的扇区数据,磁道的位置决定了数据在磁盘盘面上的圆周方向的存储位置。
- 圆柱面(Cylinder):圆柱面是由多个盘面上相同半径的磁道组成的概念,想象把多个磁盘盘片叠放在一起,处于同一垂直位置的各个盘面上的磁道就构成了一个圆柱面。在磁盘寻址时,常常先确定要访问的圆柱面,然后再在该圆柱面内的具体盘面上选择对应的磁道以及磁道中的扇区,圆柱面的概念有助于简化磁盘地址的表示和寻址操作,使得对磁盘存储位置的描述更加直观和高效。
- 磁盘容量(Disk capacity):
- 计算方式与因素:磁盘容量主要取决于磁盘的面数(即盘片的数量)、每个盘面的磁道数、每个磁道的扇区数以及每个扇区存储的数据量。其计算公式大致为:磁盘容量 = 面数 × 磁道数 × 扇区数 × 扇区容量。例如,一个磁盘有 4 个盘片(共 8 个盘面,因为每个盘片有上下两个盘面可用于存储数据),每个盘面有 1000 条磁道,每条磁道有 64 个扇区,每个扇区容量为 512 字节,那么该磁盘的容量就是 8 × 1000 × 64 × 512 字节 = 26843545600 字节(约 256GB)。不同类型和规格的磁盘,其面数、磁道数、扇区数以及扇区容量等参数会有所不同,从而导致磁盘容量也存在差异,并且随着技术的发展,磁盘容量在不断地增大,以满足人们对存储大量数据的需求。
Chapter 2 Machine Instructions
1. 指令与指令排序(Instruction and Instruction Sequencing)
① 寄存器传输与汇编语言表示法(Register Transfer & Assembly Language Notation)
- 寄存器传输:
在计算机的运算过程中,数据经常在寄存器之间进行传输和处理,寄存器传输描述了数据如何从一个寄存器移动到另一个寄存器,或者在寄存器与其他存储部件(如内存等)之间流动,同时还涉及到对数据进行的操作(如算术运算、逻辑运算等)。例如,一个简单的寄存器传输语句可以表示为
R1 <- R2 + R3,其含义是把寄存器R2和R3中的数据相加,然后将结果存入寄存器R1中,它从底层逻辑上体现了计算机执行指令时数据的流动和运算情况,是理解计算机指令执行机制的基础概念之一。 - 汇编语言表示法:
汇编语言是一种面向机器的低级编程语言,它使用助记符来表示机器指令,方便程序员编写程序并理解指令的功能。比如,对于上述的寄存器传输操作,在汇编语言中可能会用类似
ADD R1, R2, R3的语句来表示(不同的汇编语言语法可能略有不同),这里ADD就是加法操作的助记符,通过这些助记符和操作数(寄存器R1、R2、R3)的组合,程序员可以按照计算机硬件的指令集规范编写程序,然后经过汇编器的转换,将汇编语言程序编译成机器语言(二进制指令代码),使得计算机能够识别并执行相应的操作,汇编语言在底层硬件编程、操作系统内核开发等对性能和硬件控制要求较高的领域有重要应用。
② RISC指令集(RISC Instruction Sets)
- 特点与原理: 精简指令集计算机(RISC)指令集的设计理念是简化指令系统,使每条指令的功能尽可能单一、规整,指令长度固定,并且大多采用简单的寄存器操作指令,减少复杂指令的数量。例如,RISC 指令集中的算术运算指令往往只完成单一的加、减、乘、除操作,不像复杂指令集计算机(CISC)那样一条指令可能包含多个操作(如既做运算又进行内存访问等复杂功能)。这种设计使得 RISC 处理器在执行指令时,硬件实现相对简单,指令的执行效率高,可以通过提高时钟频率等方式来提升整体性能,并且更利于编译器进行优化,常用于对性能要求较高、追求高效运算的应用场景,像许多现代的移动端处理器、嵌入式处理器等大多采用 RISC 架构指令集。
- 常见的 RISC 指令集示例: 如 ARM
指令集就是一种广泛应用的 RISC
指令集,它有众多的寄存器用于数据暂存和操作,指令格式相对规范简单,比如
MOV R1, #5指令就是将立即数 5 传送到寄存器R1中,通过这些简洁明了的指令组合,可以编写出各种功能的程序,实现复杂的运算和控制逻辑。
③ 指令直线排序与分支(Instruction Strait line Sequencing & Branching)
- 指令直线排序: 指令直线排序是指程序中的指令按照顺序依次执行,就像一条直线一样,从第一条指令开始,一条接一条地执行下去,没有跳转或改变执行顺序的情况。例如,一个简单的计算两个数相加并将结果存储的程序,先是从内存读取两个操作数到寄存器的指令,然后是执行加法运算的指令,最后是把结果写回内存的指令,它们依次排列,计算机按照这个顺序逐个执行指令来完成相应的功能,这种顺序执行的方式在简单的程序逻辑或者程序的线性部分中比较常见,易于理解和实现。
- 分支(Branching):
分支指令则允许程序改变正常的执行顺序,根据一定的条件判断来决定跳转到其他指令地址继续执行。比如在
if-else语句的实现中,计算机需要判断条件是否成立,如果条件成立则执行if分支内的指令,否则执行else分支内的指令,这就需要通过分支指令(如条件跳转指令)来实现。分支指令通常会检查一些标志位(由之前的运算指令设置,比如比较运算后设置的大于、小于等标志位)或者寄存器中的值,依据这些条件决定是否跳转到指定的指令地址,它大大增加了程序的灵活性和逻辑表达能力,能够实现复杂的算法和控制流程,但也使得程序的执行路径变得复杂,对处理器的指令预取、流水线等机制会带来一定的影响,需要合理设计和优化以提高执行效率。
2. 指令格式(Instruction Formats)
① 指令表示(Instruction Representation)
- 机器语言层面:
指令在机器语言中是以二进制代码的形式存在的,不同的计算机系统有其特定的指令编码规则。一条完整的机器指令通常由操作码(Opcode)和操作数地址等部分组成,操作码用于指明要执行的操作类型(如加法、减法、数据传送等),操作数地址则指出操作数所在的位置(可能是寄存器地址、内存地址等)。例如,一个简单的
8 位机器指令,假设高 3 位表示操作码,低 5
位表示操作数地址,那么二进制代码
01100101中,011就是操作码部分,代表某种特定操作,00101就是操作数地址部分,用于定位相应的操作数,计算机硬件通过对这些二进制位的解析来执行对应的指令功能。 - 与汇编语言的对应关系: 汇编语言是对机器指令的一种助记符表示,它们之间有明确的对应关系。还是以上面的例子来说,在汇编语言中可能会有对应的语句来表示这个机器指令的功能,具体的对应取决于汇编语言的语法和相应计算机的指令集规范,通过汇编器可以将汇编语言编写的程序准确地转换为机器语言的二进制指令代码,使得计算机能够按照程序员的意图进行操作。
② 常见指令地址场格式(Common Instruction Address Field Formats: Zero address Instruction, One address instruction, Two address instruction, Three address instruction)
注意这里也可能会考察大题。
- 零地址指令(Zero address Instruction):
- 特点与应用场景:零地址指令在指令格式中不明确指出操作数的地址,操作数通常隐含在运算器的累加器(一种特殊的寄存器,用于暂存运算结果等)或者堆栈(一种后进先出的数据存储结构)中。例如,在某些简单的计算器程序中,执行加法操作时,可以先将第一个操作数压入堆栈,再压入第二个操作数,然后执行一条零地址的加法指令,该指令会默认从堆栈中弹出两个操作数进行相加,并将结果再压入堆栈中,这种指令格式使得指令代码简短,常用于一些对操作数获取方式相对固定、运算较为简单且希望简化指令格式的小型系统或者特定功能模块中,像早期的一些简单计算器芯片的指令集可能就包含零地址指令。
- 示例:常见的有堆栈运算中的
PUSH(压入堆栈)和POP(弹出堆栈)操作指令,以及基于堆栈实现的算术运算指令等,它们不需要在指令中明确指定操作数的外部地址,依靠堆栈自身的操作机制来提供操作数和存储结果。
- 一地址指令(One address instruction):
- 特点与应用场景:一地址指令只指定了一个操作数的地址,另一个操作数往往默认在累加器中或者是指令隐含规定的某个固定寄存器中。例如,在一个简单的加法指令中,指令格式中给出的地址指向内存中的一个操作数,该操作数会和累加器中的数据进行相加,结果再存回累加器中,这种指令格式在早期一些计算机系统中应用较多,它相对简洁,通过合理利用累加器等固定存储部件来减少指令中操作数地址的数量,适用于对硬件资源有限、指令格式希望尽量简化但又要能完成基本运算功能的情况,比如早期的一些小型工控机的指令集设计。
- 示例:假设有指令
ADD A, [M],这里A表示累加器,[M]表示内存地址M处的数据,这条指令就是将内存地址M处的数据和累加器A中的数据相加,然后把结果存回累加器A中,体现了一地址指令的操作特点。
- 二地址指令(Two address instruction):
- 特点与应用场景:二地址指令明确指出了两个操作数的地址,这两个操作数可以来自寄存器、内存等不同位置,指令执行完操作后,通常会把结果存放到其中一个指定的操作数地址中(一般是第一个操作数地址)。这种指令格式比较灵活,能方便地实现各种数据在不同存储位置之间的运算和传递,在现代计算机的一些指令集中仍然广泛应用,它可以满足大多数常见的算术运算、逻辑运算以及数据传送等操作需求,适用于对运算灵活性要求较高、需要在不同存储部件之间频繁操作数据的情况,比如个人计算机中的许多处理器指令集都包含大量的二地址指令。
- 示例:例如
MOV R1, R2指令,它将寄存器R2中的数据传送到寄存器R1中,这里两个操作数地址就是两个寄存器地址;再比如ADD R1, R2指令,是将寄存器R1和R2中的数据相加,结果存回寄存器R1中,体现了二地址指令在数据运算和传递方面的应用特点。
- 三地址指令(Three address instruction):
- 特点与应用场景:三地址指令指定了三个操作数的地址,分别用于存放两个操作数以及运算结果,这样在执行运算时可以更加清晰明确地指定数据的来源和去向,避免了像二地址指令那样需要将结果存放到某个操作数地址中可能带来的一些混淆或限制,尤其适用于复杂的算术运算、多操作数参与的逻辑运算等情况,能够更高效地组织和完成复杂的计算任务。不过,由于要指定三个操作数地址,使得指令的长度相对较长,在一些对指令长度有严格限制或者硬件实现成本敏感的系统中应用相对较少,更多见于一些对运算性能和灵活性要求极高的高性能计算机或者特定的专业计算领域,比如一些大型科学计算服务器的指令集可能会包含较多的三地址指令。
- 示例:比如
ADD R1, R2, R3指令,表示将寄存器R2和R3中的数据相加,然后将结果存放到寄存器R1中,通过明确的三个寄存器地址指定,清晰地完成了加法运算及结果存储的操作,展示了三交流指令的功能特点。
③ 操作码格式(扩展操作码,Opcode format (expanding opcode))
- 原理与作用: 扩展操作码是一种用于增加操作码表示的指令数量的编码方式,在有限的指令字长情况下,既要保证能表示足够多的不同操作类型(操作码部分),又要能合理安排操作数地址等其他信息的编码空间。其基本思想是对操作码进行可变长度的编码,对于一些使用频率高的基本指令,分配较短的操作码;而对于那些不太常用、功能更复杂的指令,则分配较长的操作码,通过这种方式可以在不增加指令字长太多的前提下,扩充指令集的规模,使得计算机能够执行更多种类的指令。例如,在一个 16 位的指令格式中,如果固定操作码长度为 4 位,只能表示 16 种不同指令,但采用扩展操作码方式,把操作码部分可以设计成 4 位、8 位等不同长度,对于常用的简单指令用 4 位操作码表示,不常用的复杂指令用 8 位操作码表示,这样就能在 16 位的指令格式内表示更多不同功能的指令了。
- 示例与应用场景:
假设一个简单的计算机指令格式中,前几位是操作码,后几位是操作数地址相关部分。对于像数据传送、简单加法这样的常用指令,操作码可以设为
4 位,如
0001表示数据传送,0010表示加法;而对于像浮点运算、复杂的逻辑判断等不常用指令,操作码可以扩展为 8 位,如10000010表示某种浮点加法操作,通过这种操作码的扩展设计,丰富了指令集的功能,满足不同层次、不同复杂度的程序编写需求,常用于需要兼顾指令集功能丰富性和指令字长限制的计算机系统设计中,在现代通用计算机以及一些专用计算设备的指令集优化中都有重要应用。
3. 寻址方式(Addressing Modes)
几种寻址方式是必须要掌握的。
- 立即数寻址(Immediate mode)
- 定义与原理:在立即数寻址方式中,操作数直接包含在指令中。也就是说,指令的一部分位用来表示操作数的值,而不是操作数的地址。例如,在一条指令
MOV R1, #5中,#5就是立即数,这条指令的功能是将立即数5传送到寄存器R1中。这种寻址方式的优点是获取操作数速度快,因为不需要额外的内存访问来获取操作数,操作数就在指令本身之中,对于一些需要使用常数进行运算或者初始化寄存器的情况非常方便。 - 应用场景:常用于给寄存器赋初值,比如在程序开始时,将一些已知的常量(如循环计数器的初始值、数组的长度等)加载到寄存器中。在简单的算术运算和逻辑运算中,当一个操作数是固定的常量时,也会使用立即数寻址,例如
ADD R2, R1, #3,将寄存器R1中的值和立即数3相加,结果存入R2中。
- 定义与原理:在立即数寻址方式中,操作数直接包含在指令中。也就是说,指令的一部分位用来表示操作数的值,而不是操作数的地址。例如,在一条指令
- 绝对寻址(Absolute mode)
- 定义与原理:绝对寻址方式使用绝对地址来指定操作数的位置。绝对地址是一个完整的内存地址,指令中直接包含了操作数在内存中的实际地址。例如,指令
LOAD A, [1000H](假设这是一种指令格式,其中[1000H]表示内存地址为1000H的单元),这条指令会从内存地址1000H处读取数据,并将其加载到寄存器A中。这种寻址方式的优点是能够直接访问内存中的特定位置,只要知道操作数的绝对地址,就可以准确地获取操作数。 - 应用场景:适用于访问固定的内存单元,如系统的某些配置寄存器、特定的中断向量表位置等。在一些对内存布局有明确要求的程序中,当需要访问已知绝对地址的全局变量或者系统资源时,绝对寻址是一种直接有效的方式。不过,这种寻址方式对程序的可移植性有一定影响,因为绝对地址是固定的,如果程序在不同的内存布局环境下运行,可能需要修改指令中的绝对地址才能正确访问操作数。
- 定义与原理:绝对寻址方式使用绝对地址来指定操作数的位置。绝对地址是一个完整的内存地址,指令中直接包含了操作数在内存中的实际地址。例如,指令
- 寄存器寻址(Register mode)
- 定义与原理:寄存器寻址方式的操作数存放在寄存器中,指令中指定寄存器的名字来获取操作数。例如,指令
ADD R1, R2,操作数就是寄存器R1和R2中的内容,通过指令将这两个寄存器中的值相加,结果存放在R1中。这种寻址方式的优点是访问速度快,因为寄存器位于处理器内部,数据读取和写入的延迟很低,相比于内存访问,能够更快地获取操作数,从而提高指令的执行速度。 - 应用场景:在频繁进行数据运算和数据暂存的程序部分,寄存器寻址被大量使用。例如,在循环计算过程中,循环变量、中间计算结果等通常存放在寄存器中,通过寄存器寻址方式进行操作,能够高效地利用处理器的寄存器资源,快速完成计算任务。同时,在处理器内部的数据传输和控制操作中,如将一个寄存器中的状态标志传递到另一个寄存器,也会使用寄存器寻址。
- 定义与原理:寄存器寻址方式的操作数存放在寄存器中,指令中指定寄存器的名字来获取操作数。例如,指令
- 寄存器间接寻址(Register Indirect mode)
- 定义与原理:寄存器间接寻址方式中,指令指定一个寄存器,该寄存器的内容是操作数的地址,而不是操作数本身。例如,指令
LOAD A, [R1],这里[R1]表示以寄存器R1中的内容为内存地址,从该地址处读取数据并加载到寄存器A中。这种寻址方式的优点是可以通过改变寄存器中的内容来灵活地访问不同的内存位置,增加了程序对内存访问的灵活性,同时也为一些数据结构(如链表)的操作提供了方便,因为链表节点的指针通常存放在寄存器中,通过寄存器间接寻址可以方便地访问链表中的下一个节点。 - 应用场景:在处理动态分配的数据结构(如链表、树等)时经常使用。例如,在遍历链表的过程中,将链表节点的指针存放在寄存器中,通过寄存器间接寻址访问下一个节点的数据部分。在实现函数调用时,也会用到寄存器间接寻址来访问栈帧中的局部变量和参数,因为栈帧的地址通常通过寄存器来指向。
- 定义与原理:寄存器间接寻址方式中,指令指定一个寄存器,该寄存器的内容是操作数的地址,而不是操作数本身。例如,指令
- 间接寻址(Indirect mode)
- 定义与原理:间接寻址方式和寄存器间接寻址类似,但它是通过内存中的一个单元来存储操作数的地址。例如,指令
LOAD A, [[1000H]](假设的指令格式),先从内存地址1000H处读取一个值,这个值作为真正操作数的地址,然后再从这个地址读取操作数并加载到寄存器A中。这种寻址方式更加灵活,但需要两次内存访问,第一次获取操作数的地址,第二次获取操作数本身,相对来说速度较慢。 - 应用场景:在一些复杂的内存管理和数据访问场景中使用。例如,在实现动态内存分配系统时,可能会使用间接寻址来访问存储在内存中的指针数组,这些指针再指向实际分配的内存块。不过,由于其复杂性和相对较慢的访问速度,间接寻址在现代计算机指令集中使用相对较少,除非在一些特定的、对灵活性要求极高的程序部分。
- 定义与原理:间接寻址方式和寄存器间接寻址类似,但它是通过内存中的一个单元来存储操作数的地址。例如,指令
- 变址寻址(Indexed mode)
- 定义与原理:变址寻址方式是在指令中指定一个基地址(可以是寄存器或者内存地址)和一个变址值(通常是一个寄存器中的内容),操作数的地址是基地址和变址值之和。例如,指令
LOAD A, [R1 + R2],其中R1是基地址寄存器,R2是变址寄存器,先计算R1 + R2的和作为操作数的地址,然后从这个地址处读取数据并加载到寄存器A中。这种寻址方式的优点是非常适合访问数组等数据结构,通过改变变址寄存器中的值,可以方便地访问数组中的不同元素。 - 应用场景:广泛应用于数组处理和循环结构中。例如,在一个循环遍历数组的程序中,将数组的首地址存放在一个寄存器作为基地址,循环变量存放在另一个寄存器作为变址寄存器,通过变址寻址方式就可以高效地访问数组中的每个元素,如
ADD R3, [R1 + R4],可以将数组中某个元素和寄存器R3中的值相加,其中R1是数组基地址,R4是用于索引数组元素的变址寄存器。
- 定义与原理:变址寻址方式是在指令中指定一个基地址(可以是寄存器或者内存地址)和一个变址值(通常是一个寄存器中的内容),操作数的地址是基地址和变址值之和。例如,指令
4. 堆栈(Stacks)
- 堆栈的概念与结构:堆栈是一种特殊的数据结构,它遵循后进先出(LIFO - Last In First Out)的原则。可以想象成一个只能在一端进行插入(称为压入,PUSH)和删除(称为弹出,POP)操作的存储容器。在计算机中,堆栈通常是在内存中开辟的一段连续的存储区域,有一个栈顶指针(Stack Pointer)来指示栈顶元素的位置。当进行PUSH操作时,数据被存储到栈顶指针所指向的位置,然后栈顶指针向上移动(指向更高的内存地址);当进行POP操作时,栈顶指针向下移动(指向更低的内存地址),然后读取栈顶指针所指向位置的数据。
- 堆栈的操作与功能:
- 数据存储与读取:通过PUSH和POP操作实现数据的存储和读取。例如,在函数调用过程中,函数的参数、返回地址和局部变量等通常会被压入堆栈,当函数返回时,这些数据再从堆栈中弹出。这样可以有效地管理函数调用的上下文信息,保证函数调用的正确执行。
- 支持中断处理:在计算机系统发生中断时,当前程序的状态(如寄存器的值、程序计数器的值等)会被压入堆栈,以便在中断处理完成后能够恢复原来的程序执行状态。这对于实现系统的中断机制和多任务处理非常重要,保证了系统的稳定性和可靠性。
- 表达式求值:在编译原理中,堆栈可以用于表达式求值。例如,对于一个算术表达式
3 + 4 * 2,可以使用堆栈将操作数和运算符按照一定的规则压入和弹出,从而实现表达式的求值。先将3和4压入堆栈,遇到运算符“*”,弹出两个操作数进行乘法运算,结果再压入堆栈,然后遇到“+”运算符,再次弹出操作数进行加法运算,最终得到表达式的值。
5. 子程序(Subroutines)
子程序和中断的概念也是必须掌握的。
- 子程序的定义与作用:子程序也称为函数或过程,是一段可以被主程序或者其他子程序调用的独立的程序代码。它的主要作用是将一个复杂的程序分解成多个相对独立的功能模块,提高程序的可读性、可维护性和可复用性。例如,在一个大型的图形绘制程序中,可以将绘制不同图形(如圆形、矩形、三角形等)的代码分别编写成独立的子程序,当需要绘制某种图形时,主程序只需调用相应的子程序即可,而不需要在主程序中重复编写绘制各种图形的代码。
- 子程序的调用与返回机制:
- 调用过程:当主程序调用一个子程序时,首先需要保存当前的程序执行状态,包括程序计数器(PC)的值(指向主程序中下一条要执行的指令)、寄存器的值等,通常这些信息会被压入堆栈。然后将子程序的入口地址加载到程序计数器中,使得计算机开始执行子程序的代码。
- 返回过程:在子程序执行完毕后,需要返回到主程序中调用点的下一条指令继续执行。这是通过从堆栈中弹出之前保存的程序计数器的值来实现的,同时还需要恢复其他寄存器的值,使得主程序能够在原来的状态下继续执行,保证程序的正确运行。
- 参数传递与局部变量:
- 参数传递方式:在调用子程序时,主程序需要将参数传递给子程序,以便子程序能够根据参数进行相应的操作。常见的参数传递方式有传值(将参数的值复制一份传递给子程序)和传址(将参数的地址传递给子程序)。例如,在一个计算两个数之和的子程序中,如果采用传值方式,主程序将两个数的值复制给子程序,子程序在自己的代码空间中使用这些值进行计算;如果采用传址方式,主程序将两个数在内存中的地址传递给子程序,子程序通过这些地址访问并修改主程序中的数据。
- 局部变量处理:子程序内部定义的变量称为局部变量,它们只在子程序内部有效。在子程序执行过程中,局部变量通常会在堆栈或者寄存器中分配空间。例如,在一个函数内部定义了一个变量
int i,这个变量在函数被调用时会在堆栈或者寄存器中开辟存储单元,当函数返回时,这些存储单元会被释放,保证了局部变量的生命周期和作用范围仅限于函数内部。
6. CISC指令集(CISC Instruction Sets - Addressing modes; Conditional)
- CISC指令集的特点 - 寻址方式(Addressing modes):
- 丰富多样的寻址方式:复杂指令集计算机(CISC)指令集通常具有多种复杂的寻址方式,除了前面提到的基本寻址方式外,还可能包括一些更复杂的组合寻址方式。例如,可能有自动变址寻址(在指令执行过程中自动根据某种规则改变变址寄存器的值)、相对寻址(操作数地址是相对于当前指令地址的偏移量)等多种方式。这些丰富的寻址方式使得程序员在编写程序时能够更加灵活地访问内存中的数据,但也增加了指令集的复杂性和硬件实现的难度。
- 对复杂数据结构的支持:CISC指令集的寻址方式能够很好地支持复杂的数据结构。比如在处理多维数组、结构体等复杂数据结构时,可以通过复杂的寻址方式更方便地访问数据成员。例如,通过一种特殊的寻址方式可以直接访问结构体中的某个嵌套的成员,而不需要通过多个步骤来获取。
- CISC指令集的特点 - 条件指令(Conditional):
- 丰富的条件指令类型:CISC指令集中包含大量的条件指令,这些条件指令可以根据各种条件标志(如比较结果产生的大于、小于、等于标志等)来执行不同的操作。例如,有条件跳转指令(根据条件判断是否跳转到指定的指令地址)、条件传送指令(根据条件判断是否传送数据)等。这种丰富的条件指令使得CISC能够很好地实现复杂的程序逻辑,如
if - else语句、while循环等高级语言中的控制结构可以通过CISC指令集中的条件指令高效地实现。 - 硬件对条件判断的支持:CISC处理器的硬件通常会有专门的电路来处理条件判断和条件指令的执行。例如,在进行比较运算后,硬件会自动设置相应的条件标志位,后续的条件指令可以直接读取这些标志位来决定是否执行相应的操作。这种硬件支持使得条件指令的执行速度相对较快,能够有效地支持程序中的复杂逻辑控制。
- 丰富的条件指令类型:CISC指令集中包含大量的条件指令,这些条件指令可以根据各种条件标志(如比较结果产生的大于、小于、等于标志等)来执行不同的操作。例如,有条件跳转指令(根据条件判断是否跳转到指定的指令地址)、条件传送指令(根据条件判断是否传送数据)等。这种丰富的条件指令使得CISC能够很好地实现复杂的程序逻辑,如
7. RISC与CISC风格(RISC vs. CISC styles)
- 指令集复杂度:
- RISC:精简指令集计算机(RISC)指令集相对简单,指令长度固定,指令功能比较单一。例如,RISC指令集中的算术运算指令通常只完成一种基本运算,如加法指令只做加法,减法指令只做减法。这种简单的指令设计使得RISC处理器在硬件实现上更容易优化,指令的执行效率高,因为硬件不需要处理复杂的指令功能和多种可能的操作模式。
- CISC:复杂指令集计算机(CISC)指令集则较为复杂,一条指令可能包含多个操作,指令长度可变。例如,CISC指令集中可能有一条指令既完成内存读取又进行算术运算,还可能包含复杂的寻址方式。这种复杂的指令设计使得CISC指令集能够用较少的指令完成复杂的任务,但同时也增加了硬件实现的难度和指令执行的复杂性。
- 指令执行效率:
- RISC:由于RISC指令功能单一,执行速度相对较快。而且RISC处理器通常采用流水线技术,通过将指令的执行过程分解成多个阶段(如取指令、译码、执行、访存、写回等),可以让多条指令在不同阶段同时执行,提高了处理器的吞吐量。例如,在理想情况下,每个时钟周期都可以启动一条新的指令执行,大大提高了指令的执行效率。
- CISC:CISC指令执行效率因指令而异。对于简单的指令,其执行速度可能和RISC相当,但对于复杂指令,由于需要完成多个操作和复杂的寻址,执行时间可能较长。不过,CISC处理器在处理复杂任务时,由于可以用较少的指令完成任务,在某些情况下也能表现出较高的效率,尤其是在一些不需要高时钟频率但对代码密度要求较高的应用场景中。
- 代码密度:
- RISC:RISC指令集由于指令功能单一,要完成复杂的任务通常需要更多的指令,因此代码密度相对较低。这意味着RISC程序在存储时可能需要占用更多的内存空间,但在现代计算机系统中,内存容量通常较大,这个问题相对不那么严重。而且,通过编译器优化等手段,可以在一定程度上提高RISC代码的密度。
- CISC:CISC指令集的代码密度相对较高,因为一条复杂指令可以完成多个操作,在相同的功能下,CISC程序可能比RISC程序使用更少的指令,从而占用较少的内存空间。这在一些内存资源有限的应用场景(如早期的嵌入式系统)中是一个重要的优势。
- 应用场景:
- RISC:RISC架构适用于对性能要求较高、追求高效运算和高时钟频率的应用场景,如移动设备(智能手机、平板电脑等)、高性能服务器等。在这些场景中,处理器需要快速执行大量的指令,RISC的简单指令集和高效的流水线技术能够满足这种需求。
- CISC:CISC架构则在一些对代码密度要求较高、需要用较少的指令完成复杂任务的场景中表现出色,如早期的个人计算机(因为当时内存资源有限)、一些复杂的工业控制系统等。在这些场景中,复杂的指令集可以减少程序的长度,降低存储成本和程序加载时间。
Chapter 5 Basic Processing Unit
1. 指令执行:五个步骤(Instruction Execution: five steps)
- 取指令(Instruction Fetch):这是指令执行的第一步,处理器从主存储器中读取要执行的指令。通常,程序计数器(PC)会指向当前要取的指令在内存中的地址,根据这个地址,通过地址总线将地址信息发送到内存,内存再将对应地址处的指令通过数据总线传回到处理器中,然后程序计数器会自动指向下一条待取指令的地址(一般按顺序指向下一条,除非遇到分支等改变执行顺序的指令),此步骤为后续指令的译码及执行等操作奠定基础。
- 指令译码(Instruction Decode):取到的指令在这一步被译码,也就是对指令的二进制编码进行解析,识别出指令的操作码(Opcode)以及操作数地址等相关信息。例如,确定这条指令是加法指令、减法指令还是数据传送指令等,并根据操作数地址的格式找出操作数所在的位置(是在寄存器、内存还是以其他寻址方式确定的位置),以便后续准确地执行相应操作,译码过程由处理器中的译码电路来完成。
- 执行操作(Execute Operation):基于译码得到的信息,执行指令所规定的具体操作。如果是算术运算指令,比如加法指令,就会将相应操作数从寄存器或内存等位置取出(根据寻址方式),送到算术逻辑单元(ALU)进行加法运算;若是逻辑运算指令,则在ALU中进行相应逻辑操作;如果是数据传送指令,就按照要求将数据从源位置传送到目标位置等,这一步是指令功能实现的核心环节。
- 访存(Memory Access):在有些指令执行过程中,需要访问主存储器,比如读取操作数或者存储运算结果等情况。这一步就是根据指令要求进行相应的内存访问操作。若指令是从内存读取数据到寄存器,就会将内存地址发送到内存,获取对应的数据;若要把寄存器中的数据写回内存,就会将数据和相应的内存地址信息传递给内存进行写入,该步骤体现了处理器与主存之间的数据交互需求。
- 写回结果(Write Back):将执行操作得到的结果写回到相应的存储位置,通常是寄存器或者内存中(取决于指令规定以及数据的后续用途等)。例如,算术运算的结果可能写回某个指定的寄存器,以便后续指令继续使用这个结果进行其他运算或处理,完成整个指令执行的最后一环,保证指令执行结果能够被正确保存和后续利用。
2. 硬件组件:五个阶段(Hardware Components: five stages)
- 取指部件(Instruction Fetch Unit):主要负责完成取指令的操作,包括与程序计数器(PC)配合,根据PC指向的地址从主存获取指令,并将指令传送到下一个处理阶段,同时更新PC的值,使其指向下一条待取指令,其包含地址生成电路、指令缓存等相关组件,用于高效准确地获取指令。
- 译码部件(Instruction Decode Unit):接收取指部件传来的指令,运用译码电路对指令的二进制代码进行解读,提取出操作码、操作数地址等关键信息,为后续执行操作阶段提供明确的执行依据,该部件会与处理器的寄存器堆等有连接,以便确定操作数的具体来源等情况。
- 执行部件(Execute Unit):由算术逻辑单元(ALU)以及相关的控制电路等组成,根据译码得到的指令信息,驱动ALU完成具体的算术运算、逻辑运算等操作,还可能涉及到移位器、乘法器等其他运算组件(具体取决于处理器的功能支持),是实际执行指令功能的核心硬件区域。
- 访存部件(Memory Access Unit):用于处理指令执行过程中与主存储器之间的数据交互需求,具备地址转换电路(如果有虚拟内存机制等)、数据缓存等功能模块,能够根据指令要求准确地向主存发送读或写的请求,并完成数据的传输,确保内存访问的顺利进行。
- 写回部件(Write Back Unit):负责将执行部件产生的结果或者访存后的数据等,按照指令要求准确地写回到指定的寄存器或内存位置,通过与寄存器堆、数据总线以及内存等的连接,完成结果的最终保存,保障整个指令执行流程的完整性。
3. 指令获取与执行步骤(Instruction Fetch and Execution Steps)
- 整体流程关联:指令获取与执行步骤其实就是上述五个步骤的循环过程,处理器不断地从主存获取指令,依次经过译码、执行、访存(如果需要)、写回等环节,一条指令执行完毕后,接着获取下一条指令继续这个流程,从而实现程序的持续运行。在这个过程中,不同的指令可能会根据其功能特点在某些步骤上有不同的操作侧重,比如数据传送指令可能没有执行复杂运算的过程,而算术运算指令则重点在执行操作阶段进行运算。
- 流水线角度(可选补充,如果有相关知识拓展需求):从流水线的角度来看,为了提高处理器的执行效率,可以将这五个步骤看作流水线上的不同阶段,多条指令可以在不同阶段同时进行处理,就像工厂生产线上不同环节同时加工不同的产品一样。例如,第一条指令在执行操作阶段时,第二条指令可以正在进行译码,第三条指令在取指阶段等,通过这种并行处理的方式,能在单位时间内处理更多的指令,提升处理器的整体性能,但同时也需要处理好各阶段之间的数据传递、指令依赖等问题,避免出现流水线阻塞等影响效率的情况。
4. 控制信号(Control Signals)
- 定义与作用:控制信号是由处理器的控制单元产生的,用于协调和指挥处理器内部各个硬件部件(如取指部件、译码部件、执行部件等)以及与外部部件(如主存储器)之间按照正确的顺序和方式进行操作的电信号。例如,控制信号可以决定何时启动取指操作、是将数据从寄存器读入ALU还是从内存读入ALU进行运算、运算结果是写回寄存器还是写回内存等,它们就像是交通信号灯一样,指引着数据和指令在处理器及相关部件之间有序流动,保障指令执行流程的准确实现。
- 分类与示例(简单举例):
- 操作码相关控制信号:根据不同的操作码产生对应的控制信号,比如对于加法操作码,会产生控制信号使ALU执行加法运算功能,同时协调相关寄存器和数据通路打开,让操作数能正确送到ALU进行相加;对于数据传送操作码,会有控制信号控制数据从源地址传送到目标地址,打开相应的寄存器或内存读写端口等。
- 时序相关控制信号:按照指令执行的先后顺序,在不同的时间节点产生不同的控制信号。例如,在取指阶段,会有控制信号通知程序计数器输出地址、内存接收地址并返回指令等;在写回阶段,会产生控制信号控制写回部件在合适的时间将结果写入正确的位置,这些信号要严格按照处理器的时钟周期和指令执行节拍来产生和发送,保证各部件有条不紊地协同工作。
5. 控制信号的产生(Generation of Control Signals)
- 硬连线控制(Hardwired Control (RISC processor)):
- 原理与特点:硬连线控制是一种通过硬件电路直接生成控制信号的方式,它将控制信号的生成逻辑直接用组合逻辑电路(如门电路等)和时序逻辑电路(包含触发器等,用于实现记忆和时序控制功能)实现。对于RISC处理器来说,由于其指令集相对简单、指令格式较为规整,采用硬连线控制可以利用硬件电路的高速特性,使控制信号的产生速度很快,能高效地配合简单指令的快速执行。在这种方式下,控制信号的产生取决于当前的指令操作码、指令执行阶段以及处理器的状态(如标志位等)等因素,硬件电路根据这些输入直接输出相应的控制信号,没有中间的软件层面的转换过程,一旦硬件电路设计完成,其控制信号生成逻辑就固定下来了。
- 优点与缺点:优点是执行速度快,因为直接由硬件电路生成控制信号,不存在软件解释或读取额外存储结构的时间开销,非常适合对速度要求高的RISC处理器,能充分发挥其简单指令高效执行的优势;缺点是硬件电路设计复杂且缺乏灵活性,一旦设计好后,如果要修改或扩展指令集,就需要对硬件电路进行重新设计和布线,成本较高,难度也较大,所以不利于指令集的频繁更新和扩展。
- 微程序控制(Microprogramming (CISC processor)):
- 微指令(控制字,Microinstruction (control word)):微指令也叫控制字,它是微程序控制中的基本单元,一条微指令定义了处理器在一个微操作周期内要执行的一组微操作,也就是规定了对处理器内部各个硬件部件的具体控制信号状态。例如,一条微指令可以规定ALU执行何种运算、哪些寄存器要进行读写、数据通路如何连接等,它是对硬件操作的一种细致描述,通过一系列微指令的组合来实现复杂的指令功能。
- 微程序(微例程,Microprogram (microroutine)):微程序是由一组微指令按照一定的顺序排列组成的,对应着一条机器指令的功能实现。也就是说,每一条机器指令在微程序控制下都有一个专门的微程序来执行它,这个微程序中的微指令会按照顺序依次执行,指挥处理器完成该机器指令对应的所有操作。例如,对于一条复杂的CISC指令(如既包含算术运算又涉及内存访问等多步操作的指令),其对应的微程序会有多个微指令,分别完成取操作数、执行运算、访问内存、写回结果等一系列微操作,通过微程序的执行将复杂的机器指令功能拆解为多个简单微操作来实现。
- 控制存储(Control Store):控制存储是用于存放微程序的存储器,通常是只读存储器(ROM)或者可写的控制存储器(根据不同的应用场景和处理器设计)。微程序以二进制代码的形式存储在控制存储中,当处理器要执行一条机器指令时,会根据该指令的操作码等信息到控制存储中查找对应的微程序,然后依次取出微指令进行执行,从而产生相应的控制信号来控制处理器完成指令的执行,控制存储的容量大小取决于处理器指令集的规模以及微程序的复杂程度等因素。
- 硬连线控制与微程序控制对比(Hardwired Control vs.
Microprogramming):
- 灵活性方面:
- 硬连线控制:灵活性较差,如前面所述,一旦硬件电路设计好,更改指令集或添加新指令就很困难,因为需要对硬件电路进行大规模改动,涉及重新布线、调整逻辑门等复杂操作,成本高昂且耗时。
- 微程序控制:具有较好的灵活性,通过修改微程序(也就是控制存储中的内容)就可以相对容易地改变指令的执行方式或者添加新的指令功能,不需要对硬件电路进行大的改动,只要控制存储有足够的空间且微指令的编码格式允许,就可以方便地对指令集进行扩展或调整,便于处理器的升级和功能优化。
- 执行速度方面:
- 硬连线控制:由于直接由硬件电路快速生成控制信号,没有额外的存储读取和微指令解释等过程,所以执行速度通常较快,能满足RISC处理器对指令快速执行的要求,在对性能要求较高、追求高时钟频率的场景中表现出色。
- 微程序控制:相对来说执行速度会稍慢一些,因为在执行指令时需要先从控制存储中读取微指令,然后再根据微指令内容产生控制信号,这个过程涉及到存储器访问和微指令的译码等环节,会引入一定的时间延迟,不过随着技术发展,这种速度差异在一些应用场景中已经逐渐缩小。
- 设计复杂度方面:
- 硬连线控制:硬件电路设计非常复杂,需要精心设计组合逻辑电路和时序逻辑电路来准确生成各种控制信号,对于设计人员的专业能力和经验要求很高,而且设计过程中要考虑到各种指令、不同执行阶段以及可能出现的处理器状态变化等众多因素,设计周期较长。
- 微程序控制:硬件设计相对简单,主要重点在于设计微程序以及控制存储的相关结构,将很多控制逻辑通过软件化的微程序方式实现,减轻了硬件设计的负担,但同时需要对微程序进行精心编写和调试,以确保微程序能够正确地实现所有机器指令的功能,不过总体上设计复杂度低于硬连线控制。
- 应用场景方面:
- 硬连线控制:主要应用于RISC处理器,适合那些指令集简单、追求高效执行速度、对灵活性要求不高的场景,如移动设备中的处理器、高性能服务器中的部分核心处理单元等,这些场景更看重指令的快速执行以提高系统整体性能。
- 微程序控制:常用于CISC处理器,在处理复杂指令、需要方便地扩展指令集以及对硬件设计成本和复杂度有一定控制要求的场景中更具优势,像早期的个人计算机处理器、一些工业控制领域使用的复杂指令集处理器等,利用其灵活性来满足多样化的功能需求。
- 灵活性方面:
Chapter 6 Pipelining
1. 基本概念(Basic Concepts)
① 流水线(Pipelining)
- 定义与原理:流水线是一种提高处理器执行效率的技术,它将指令的执行过程划分为多个不同的阶段,使得多条指令能够在这些阶段中重叠进行执行。就好比工厂的生产流水线,将产品制造的全过程分成多个工序,不同的产品可以同时处于不同的工序上进行加工,这样在同一时间内可以有多个产品处于生产流程中,整体生产效率得以提升。在处理器中,例如一条指令的执行原本要依次经过取指令、译码、执行、访存、写回等步骤,采用流水线技术后,当第一条指令处于执行阶段时,第二条指令可以进行译码阶段,第三条指令在取指令阶段等,通过这种方式让处理器在每个时钟周期都能启动一条新指令的执行(理想情况下),充分利用硬件资源,提高指令的吞吐量。
- 优势与意义:通过让指令重叠执行,能够有效减少处理器等待的时间,增加单位时间内完成的指令数量,进而提高整个处理器的性能。尤其是对于现代复杂的计算机系统,需要快速处理大量指令,流水线技术的应用使其可以在不显著增加硬件成本的基础上,实现更高的运算速度和数据处理能力,满足多任务、高性能应用程序的运行需求。
② 速率(Rate)
- 含义与目标:流水线的速率通常以“一个指令每周期(one instruction per cycle)”来描述其理想状态下的执行效率目标,也就是希望在每个时钟周期都能有一条指令完成执行流程并流出流水线。当然,这是一种理想化的情况,在实际的流水线运行中,可能会由于各种因素(如数据依赖、分支预测错误、资源冲突等)导致无法达到这个理想速率,但它为衡量流水线性能提供了一个参考标准,处理器设计和优化往往会朝着尽量接近这个理想速率的方向努力,通过解决各种可能影响流水线顺畅运行的问题,来提高实际的指令执行速率。
2. 流水线组织(Pipeline Organization)
① 五个阶段(Five stages: Fetch, Decode, Compute, Memory, Write)
- 取指阶段(Fetch):
- 功能与操作:这是流水线的第一个阶段,负责从主存储器中获取指令。程序计数器(PC)会指向当前要取的指令在内存中的地址,然后通过地址总线将地址信息发送到内存,内存根据该地址返回对应的指令,再通过数据总线将指令传回到处理器中,同时,程序计数器会自动更新,指向下一条待取指令的地址(通常按顺序指向下一条,除非遇到分支等改变执行顺序的指令)。此阶段为后续的指令译码及整个指令执行流程奠定基础,就如同流水线上产品生产的第一道工序,准备好后续加工所需的“原材料”(指令)。
- 重要性与影响因素:取指阶段的效率会受到主存储器的访问速度、程序计数器更新的准确性以及指令缓存(如果有)的命中率等因素影响。例如,如果指令缓存命中率高,能直接从缓存中获取指令,就可以加快取指速度,减少从主存读取指令的等待时间,进而提升整个流水线的效率。
- 译码阶段(Decode):
- 功能与操作:取到的指令在译码阶段被解析,也就是对指令的二进制编码进行识别,确定其操作码(Opcode)以及操作数地址等关键信息。处理器中的译码电路会判断这条指令是执行何种操作(如加法、减法、数据传送等),并依据操作数地址的格式找出操作数所在的位置(是在寄存器、内存还是通过其他寻址方式确定的位置),以便后续阶段能够准确地执行相应操作,如同生产线上对“原材料”进行分类和标记,明确后续如何“加工”它。
- 影响因素与处理方式:指令集的复杂度会对译码阶段产生影响,复杂指令集(CISC)由于指令格式多样、功能复杂,译码难度相对较大;而精简指令集(RISC)指令格式较为规整、功能单一,译码会更简单快捷。为了提高译码效率,处理器通常会采用一些优化技术,如指令预译码、增加译码电路并行度等,确保能够快速准确地解读指令信息,使指令顺利进入下一个执行环节。
- 计算阶段(Compute):
- 功能与操作:基于译码阶段得到的信息,在计算阶段执行指令所规定的具体运算操作。如果是算术运算指令,相应的操作数会从寄存器或内存等指定位置取出(根据指令的寻址方式),送到算术逻辑单元(ALU)进行运算;若是逻辑运算指令,则在ALU中进行对应的逻辑操作;对于其他类型的指令(如移位指令等),也会通过相应的运算部件完成规定的操作。这个阶段是指令功能实现的核心环节,相当于生产线上对产品进行实质性“加工制造”的过程。
- 硬件支持与优化方向:计算阶段依赖于算术逻辑单元(ALU)以及相关的辅助运算部件(如乘法器、移位器等)的性能,为了提高运算速度,处理器会不断优化这些运算部件的结构和运算能力,比如采用更快的加法器电路、并行的乘法器设计等。同时,还需要处理好不同指令在运算资源上可能出现的冲突情况,通过合理的资源分配和调度机制,保证各指令能够顺利完成运算,避免因资源争用导致流水线阻塞。
- 访存阶段(Memory):
- 功能与操作:有些指令在执行过程中需要访问主存储器,访存阶段就是根据指令要求进行相应的内存访问操作。若指令是从内存读取数据到寄存器,就会将内存地址发送到内存,获取对应的数据;若要把寄存器中的数据写回内存,就会将数据和相应的内存地址信息传递给内存进行写入,实现处理器与主存储器之间的数据交互,类似生产线上对加工好的产品进行必要的“包装”或“存储”环节,确保数据能在合适的地方进行保存或获取。
- 关键问题与解决措施:访存阶段面临的主要问题是可能出现的存储器访问冲突,例如多条指令同时要访问同一内存地址或者访问存储器的带宽限制等情况。为解决这些问题,处理器采用了诸如数据缓存、内存访问仲裁、多通道内存等技术,通过缓存常用数据减少对主存的频繁访问,通过仲裁机制协调不同指令的访问顺序,利用多通道内存增加访问带宽,从而保障访存阶段的顺畅进行,维持流水线的高效运行。
- 写回阶段(Write):
- 功能与操作:将执行阶段得到的结果写回到相应的存储位置,通常是寄存器或者内存中(取决于指令规定以及数据的后续用途等)。例如,算术运算的结果可能写回某个指定的寄存器,以便后续指令继续使用这个结果进行其他运算或处理,完成整个指令执行的最后一环,就像生产线上将最终的产品“入库”,保证指令执行结果能够被正确保存和后续利用。
- 相关考虑因素:写回阶段需要注意写操作的顺序和正确性,避免出现数据覆盖错误等问题。特别是在流水线环境下,可能有多条指令同时涉及写回操作,要根据指令的先后顺序和依赖关系合理安排写回的时机,同时要保证写回的数据能够准确无误地到达指定位置,这通常需要通过严格的控制信号和数据通路设计来实现。
② 级间缓冲器(Inter stage buffers)
- 作用与原理:级间缓冲器放置在流水线各个阶段之间,主要起到临时存储数据和指令的作用,用于隔离不同阶段,使它们能够相对独立地工作,避免前后阶段之间的相互干扰。例如,在取指阶段和译码阶段之间设置缓冲器,取指阶段获取到的指令可以先暂存在缓冲器中,等待译码阶段准备好接收时再传递过去,这样即使取指阶段因为某些原因(如主存访问延迟稍长)暂时无法及时提供新指令,译码阶段也可以基于缓冲器中已有的指令继续工作一段时间,不会立刻出现空闲等待的情况,保证了流水线的连续性和稳定性。
- 类型与特点:常见的级间缓冲器有寄存器堆、先进先出(FIFO)队列等形式。寄存器堆可以快速地进行数据读写操作,适合存储需要快速访问和处理的指令及数据;FIFO队列则按照数据进入的先后顺序依次输出,在一些需要保证数据顺序的流水线段之间应用较多,不同类型的缓冲器根据具体的流水线阶段特点和需求进行选择和配置,共同保障流水线各阶段之间数据的平稳传递和高效衔接。
- 对流水线性能的影响:级间缓冲器虽然增加了一定的硬件成本和数据传输延迟(因为数据需要经过缓冲器的存储和读取过程),但总体上对提升流水线性能有着重要作用。它能够缓解因不同阶段速度差异、数据依赖等问题带来的流水线阻塞风险,通过缓冲数据和指令,让流水线各阶段可以按照自己的节奏进行工作,更好地实现指令的重叠执行,从而提高整个流水线的效率和吞吐量。
3. 流水线问题(Pipeline issues (hazards))
① 数据依赖(Data dependencies)
- 数据依赖的产生:在指令执行过程中,当一条指令的执行结果要作为后续指令的操作数时,就会产生数据依赖关系。例如,指令
ADD R1, R2, R3(将R2和R3相加,结果存入R1)后面跟着一条指令SUB R4, R1, R5(用R1中的值和R5做减法,结果存入R4),那么第二条指令SUB就依赖于第一条指令ADD的执行结果,因为它需要R1中正确的相加结果才能进行减法运算。这种依赖关系在流水线环境下可能会引发问题,因为按照流水线的并行执行机制,多条指令处于不同的执行阶段,如果后续依赖前面结果的指令过早地获取操作数,可能会得到错误的数据,进而影响程序的正确性。 - 流水线停顿(pipeline stalling):
- 原理与操作:为了解决数据依赖导致的潜在错误,一种常见的方法是流水线停顿,也叫流水线阻塞(pipeline
blocking)。当检测到存在数据依赖时,流水线会暂停后续相关指令的执行,让依赖关系中前面的指令先完成执行并将正确结果写回相应位置后,后续指令再继续执行。例如,在上述的
ADD和SUB指令示例中,如果检测到SUB指令依赖ADD指令的结果,在ADD指令还未将结果写回R1时,流水线会让SUB指令所在阶段(如取指后的译码、计算等阶段)暂停,等待ADD指令完成写回操作,确保SUB指令获取到正确的R1值后再继续往下执行流水线的各个阶段,这样虽然会牺牲一定的流水线执行效率,但能保证程序执行结果的正确性。 - 优缺点:优点是能够简单直接地避免因数据依赖产生的数据错误,保证程序逻辑按照预期执行;缺点是会使流水线的效率降低,因为停顿意味着在这段时间内流水线没有新的指令在推进,浪费了一些时钟周期,特别是当程序中存在较多的数据依赖情况时,频繁的停顿可能会导致整体性能明显下降。
- 原理与操作:为了解决数据依赖导致的潜在错误,一种常见的方法是流水线停顿,也叫流水线阻塞(pipeline
blocking)。当检测到存在数据依赖时,流水线会暂停后续相关指令的执行,让依赖关系中前面的指令先完成执行并将正确结果写回相应位置后,后续指令再继续执行。例如,在上述的
- 操作数前送(operand forwarding):
- 原理与操作:操作数前送又称数据前推,是另一种解决数据依赖问题的策略,它的核心思想是在数据还未正式写回寄存器之前,直接将其从产生结果的地方(如执行阶段的算术逻辑单元输出端等)传递给后续依赖该数据的指令,使得后续指令不用等待前面指令完全写回结果就能获取到正确的操作数继续执行。继续以上面
ADD和SUB指令为例,当ADD指令在执行阶段算出结果后,不是等写回阶段将结果存入R1再让SUB指令获取,而是直接把执行阶段得到的结果通过专门的数据通路“前送”给正在译码或准备进入计算阶段的SUB指令,这样SUB指令就可以及时利用这个正确结果继续执行,减少了流水线停顿的时间,提高了流水线的运行效率。 - 实现方式与优势:实现操作数前送需要在处理器的硬件设计中增加额外的数据通路以及相应的控制逻辑,用于检测数据依赖情况并在合适的时候进行数据的前送操作。其优势在于在保证程序正确性的基础上,能够有效减少因数据依赖导致的流水线停顿,提高流水线的指令吞吐量,相比于单纯的流水线停顿策略,更有利于发挥流水线并行执行指令的优势,提升处理器的整体性能,在现代处理器设计中被广泛应用。
- 原理与操作:操作数前送又称数据前推,是另一种解决数据依赖问题的策略,它的核心思想是在数据还未正式写回寄存器之前,直接将其从产生结果的地方(如执行阶段的算术逻辑单元输出端等)传递给后续依赖该数据的指令,使得后续指令不用等待前面指令完全写回结果就能获取到正确的操作数继续执行。继续以上面
② 存储器延迟(Memory delays)
- 存储器延迟的影响:在流水线的访存阶段,如果对主存储器进行访问,由于存储器本身的访问速度相对较慢(相较于处理器内部的操作速度),会产生一定的时间延迟。例如,一条指令需要从内存读取操作数,发起访问请求后,要等待一段时间(取决于内存的响应速度、地址译码时间、数据传输时间等因素)才能获取到数据,这个等待时间会使得流水线在访存阶段停滞,进而影响整个流水线的顺畅运行。特别是当有多条指令连续需要访存或者频繁访问内存中的不同数据时,这些延迟积累起来会严重拖慢流水线的执行速度,降低处理器的性能。
- 应对措施:
- 数据缓存(Data cache):通过在处理器内部设置数据缓存,将近期可能会频繁访问的内存数据存储在缓存中。当指令需要访问数据时,首先在缓存中查找,如果命中缓存(即找到所需数据),就可以快速获取数据,避免了直接访问主存带来的长延迟,大大缩短了访存阶段的时间,提高流水线效率。例如,在循环结构中,循环内频繁使用的数组元素等数据可以提前加载到缓存中,后续指令访问这些数据时就能快速响应,减少因访存延迟导致的流水线停顿。
- 指令预取(Instruction prefetching):提前预测将要执行的指令,并将其从主存取到指令缓存中,使得取指阶段能够更快地获取指令,减少取指时等待主存响应的时间。通过分析程序执行的规律(如顺序执行、循环执行等特点),处理器可以提前发出取指请求,将后续可能用到的指令提前准备好,保证流水线的取指环节能够持续稳定地为后续阶段提供指令,缓解因访存延迟对流水线整体性能的影响。
- 多端口存储器(Multi-port memory):采用多端口的存储器设计,允许同时进行多个独立的读或写操作,这样在流水线中有多条指令需要同时访问存储器时(比如一条指令读数据,另一条指令写数据等情况),可以通过不同的端口并行进行访问,减少相互等待的时间,提高存储器的访问效率,从而保障流水线在访存阶段能够更顺畅地运行。
③ 资源限制(Resource limitations)
- 资源限制的体现:在流水线中,不同阶段会使用到各种硬件资源,如算术逻辑单元(ALU)、寄存器堆、数据通路等,当多条指令在同一时间需要使用同一种有限的硬件资源时,就会出现资源限制问题,也就是资源冲突。例如,在计算阶段,如果有多条指令都需要使用 ALU 进行算术运算,而 ALU 在同一时刻只能处理一个运算任务,那么就会出现资源争用的情况,导致部分指令无法及时执行,只能等待 ALU 空闲下来,进而影响流水线的正常推进,使流水线效率下降。
- 解决方法:
- 资源复用与分时共享:合理安排硬件资源,让其在不同的时钟周期或不同的指令阶段能够被复用。比如,对于 ALU,可以设计在一个时钟周期内先处理一条指令的加法运算,下一个时钟周期再处理另一条指令的减法运算,通过分时共享的方式,尽可能满足多条指令对同一资源的需求,提高资源的利用率,减少因资源冲突导致的流水线停顿。
- 增加资源数量:在硬件成本和芯片面积等允许的情况下,适当增加关键资源的数量。例如,增加 ALU 的个数,当有多条指令需要进行算术运算时,多条 ALU 可以同时工作,并行处理不同指令的运算任务,避免了因争抢同一个 ALU 而出现的等待情况,能够有效提升流水线在执行阶段的处理能力,加快指令的执行速度,保障流水线的高效运行,不过这种方式会增加硬件成本和芯片复杂度,需要在性能提升和成本之间进行权衡。
- 指令调度(Instruction scheduling):通过编译器或者硬件的动态调度机制,对指令的执行顺序进行重新调整,尽量避免多条指令在同一时间对同一资源的集中需求。例如,编译器在编译程序时,可以分析指令之间的依赖关系和资源使用情况,将不相互依赖且对资源需求不同的指令交错排列,使得它们在流水线中执行时能够更均匀地使用各种资源,减少资源冲突发生的概率,优化流水线的执行效率,这需要编译器具备较强的指令调度优化能力以及硬件提供一定的支持来实现动态调度功能。
④ 分支延迟(Branch delays)
- 分支延迟的原因:在程序执行过程中,遇到分支指令(如条件跳转指令、无条件跳转指令等)时,流水线会面临一个问题。因为流水线是按照顺序预取和执行指令的,而分支指令会改变程序的执行顺序,在分支指令执行完毕之前,流水线并不知道后续应该取哪些指令继续执行,例如,一条条件跳转指令需要根据之前运算结果设置的条件标志来判断是否跳转,如果按照流水线正常的顺序取指,可能取到的是跳转目标地址之外的指令,导致取到的这些指令白白执行了一部分(在确定要跳转后,这些取错的指令就需要丢弃),浪费了流水线的执行资源,产生了分支延迟,影响了流水线的效率。
- 解决策略:
- 分支预测(Branch prediction):这是一种常用的解决分支延迟问题的方法,处理器通过硬件的分支预测器,根据历史的分支执行情况(如某条分支指令之前多次执行时是跳转还是不跳转等信息)或者当前指令的一些特征,提前预测分支指令是否会跳转以及跳转的目标地址,然后按照预测的结果提前去取相应的指令放入流水线继续执行。如果预测正确,流水线就能顺畅运行,避免了因等待分支确定而产生的停顿;如果预测错误,则需要清空已经错误取到并执行了一部分的指令,重新从正确的分支目标地址取指执行,虽然预测错误会有一定代价,但总体上通过合理准确的分支预测能够有效减少分支延迟对流水线性能的影响,提高流水线的执行效率。
- 延迟槽(Delay slots):有些处理器采用设置延迟槽的方式来处理分支延迟,即在分支指令后面紧跟的几个指令槽(通常是 1 - 3 个,具体数量因处理器而异)被定义为延迟槽,无论分支指令最终是否跳转,延迟槽中的指令都会被执行。编译器会尽量将那些不受分支结果影响、对程序逻辑没有破坏的指令放入延迟槽中,这样可以利用原本可能被浪费的流水线周期来执行一些有用的指令,一定程度上缓解分支延迟带来的性能损失,不过这种方法需要编译器和硬件之间有良好的配合,并且对可放入延迟槽的指令有一定限制,其优化效果相对有限,在现代处理器设计中已逐渐不占主导地位,但在一些特定的处理器架构中仍有应用。
Chapter 3 Basic Input/Output
1. I/O设备的寻址方式(Addressing Modes of I/O Devices: memory mapped I/O, Isolated I/O)
- 内存映射I/O(memory mapped I/O):
- 原理:在这种寻址方式下,I/O设备被当作内存的一部分进行编址,I/O端口占用了内存地址空间中的特定地址范围。处理器访问I/O设备就如同访问内存单元一样,使用相同的指令(如用于读写内存的加载和存储指令)来操作I/O设备对应的地址。例如,若某个设备的控制寄存器被映射到内存地址空间的0x1000位置,那么处理器可以通过执行
LOAD指令从地址0x1000读取该寄存器的状态,或者通过STORE指令向该地址写入数据来对设备进行控制,这种方式使得I/O操作与内存操作在编程上具有一致性,简化了程序设计。 - 优点与缺点:优点是编程简单方便,软件开发人员可以用熟悉的内存操作方式来处理I/O,无需专门学习不同的I/O指令集;硬件设计上也相对简洁,减少了指令系统的复杂度。缺点是会占用一部分内存地址空间,对于内存资源紧张的系统可能不太友好,而且所有对这些地址的访问都需要经过内存管理单元(如果有)的地址转换等操作,可能会在一定程度上影响访问速度。
- 原理:在这种寻址方式下,I/O设备被当作内存的一部分进行编址,I/O端口占用了内存地址空间中的特定地址范围。处理器访问I/O设备就如同访问内存单元一样,使用相同的指令(如用于读写内存的加载和存储指令)来操作I/O设备对应的地址。例如,若某个设备的控制寄存器被映射到内存地址空间的0x1000位置,那么处理器可以通过执行
- 独立I/O(Isolated I/O):
- 原理:独立I/O为I/O设备分配了独立于内存地址空间的专门I/O地址空间,处理器有专门用于I/O操作的指令(如
IN指令用于从I/O端口输入数据,OUT指令用于向I/O端口输出数据),通过这些特定的I/O指令和对应的I/O地址来与设备进行交互。例如,使用OUT 0x30, AL指令可以将寄存器AL中的数据发送到I/O地址为0x30的设备端口,实现对设备的输出控制,它明确区分了内存操作和I/O操作,各自有独立的地址和指令体系。 - 优点与缺点:优点是不占用内存地址空间,使得内存空间能够更纯粹地用于存储数据和程序,并且由于有专门的I/O指令,对于I/O操作的针对性更强,执行效率可能相对较高。缺点是指令系统相对复杂一些,程序员需要掌握专门的I/O指令来编写I/O相关程序,而且硬件上需要额外设计I/O地址译码等相关电路,增加了硬件的复杂度。
- 原理:独立I/O为I/O设备分配了独立于内存地址空间的专门I/O地址空间,处理器有专门用于I/O操作的指令(如
2. 程序控制I/O的原理(Principle of program controlled I/O)
- 基本原理:程序控制I/O是一种由处理器主动控制I/O设备进行数据传输的方式,整个数据传输过程完全在程序的指令控制下完成。例如,当需要从外部设备读取数据时,处理器先向设备发送控制信号,启动设备的数据准备工作(如让磁盘驱动器开始寻道、读取数据等),然后通过不断地查询设备的状态寄存器(使用轮询的方式),判断设备是否已经准备好数据,当检测到设备数据准备好后,再执行读取数据的指令,将数据从设备端口传送到处理器内部的寄存器或者内存中。同样,在向设备输出数据时,也是先发送控制信号,然后按顺序将数据逐个传送到设备端口,整个过程依赖于处理器执行的一条条指令来推进,程序需要花费大量时间来等待I/O操作完成,导致处理器在这段时间内不能高效地做其他工作。
- 特点与局限性:这种方式的特点是简单直观,易于理解和实现,在简单的小型系统或者对I/O传输速度要求不高的场景中可以使用。然而,其局限性也很明显,由于处理器需要不断地轮询设备状态,在等待I/O操作的过程中会占用大量的处理器时间,造成处理器资源的浪费,尤其在频繁进行I/O操作或者I/O设备速度较慢的情况下,会严重影响系统的整体性能,所以在现代高性能计算机系统中较少单独使用这种方式,更多是结合其他更高效的I/O控制方式来综合运用。
3. 中断(Interrupt)
① 中断、中断请求、中断响应、中断服务程序(Interrupt, Interrupt Request, Interrupt Acknowledge, Interrupt Service Routine)
- 中断(Interrupt):中断是计算机系统中一种重要的机制,它允许外部设备或内部某些事件(如定时器溢出等)在需要时打断当前正在执行的程序,使处理器暂停当前任务,转而去处理相应的紧急事件(如读取设备准备好的数据、处理定时器超时的操作等),处理完后再返回原来被打断的程序继续执行,就如同在日常工作中突然有紧急电话打进来,先暂停手头工作去处理电话内容,之后再接着继续原来的工作一样,通过中断机制可以提高计算机系统对外部事件的响应能力和处理效率。
- 中断请求(Interrupt Request):当外部设备(如键盘有按键按下、鼠标有移动或点击操作等)或者内部特定事件发生时,相关设备或模块会向处理器发送中断请求信号,告知处理器有需要处理的事件发生了。这个信号通常通过中断请求线(在硬件上有相应的连线)发送给处理器,不同的设备可能对应不同的中断请求线或者采用中断优先级编码等方式来区分,例如,键盘可能通过中断请求线1发送中断请求,磁盘驱动器通过中断请求线2发送请求等,以便处理器识别是哪个设备或事件触发的中断。
- 中断响应(Interrupt Acknowledge):处理器在接收到中断请求信号后,如果当前允许中断(即中断没有被屏蔽,后面会讲到中断的使能和禁用情况),并且该中断请求的优先级符合处理条件(若有多个中断同时请求,按照优先级顺序处理),处理器会暂停当前正在执行的程序,发出中断响应信号,表示它已经收到并准备处理这个中断请求。然后,处理器会保存当前程序的关键信息(如程序计数器的值,也就是下一条要执行的指令地址,以及寄存器的状态等),以便后续能够准确地返回原来的程序继续执行,接着开始查找并执行对应的中断服务程序。
- 中断服务程序(Interrupt Service Routine):中断服务程序也叫中断处理程序,是一段专门用于处理特定中断事件的程序代码,它针对不同的中断源(如键盘中断、磁盘中断等)编写了相应的处理逻辑。例如,键盘中断的服务程序会负责读取键盘缓冲区中按键对应的编码信息,进行相应的字符处理(如显示在屏幕上等);磁盘中断服务程序可能会处理磁盘数据的读取或写入完成后的后续操作,如将读取的数据搬运到内存指定位置等。中断服务程序一般会被存放在内存中的特定区域,处理器通过某种方式(如根据中断向量表查找,后面会涉及)找到对应的中断服务程序入口地址,然后执行该程序来处理中断事件,处理完毕后再通过之前保存的程序信息返回原来被中断的程序继续执行。
② 子程序与中断服务程序的区别(Difference between subroutine and interrupt service routine)
- 调用时机不同:子程序是由主程序通过调用指令主动调用执行的,是程序执行流程中按照程序员预先设计好的逻辑进行调用,例如在需要执行某个特定功能(如计算一个复杂函数的值)时,主程序会明确地调用相应的子程序;而中断服务程序是由外部设备或内部事件触发中断请求后,处理器被动响应去执行的,不受主程序的直接控制,只要满足中断条件就会打断当前程序去执行对应的中断服务程序,具有随机性和突发性。
- 返回地址保存方式不同:在调用子程序时,通常是将返回地址(主程序中下一条要执行的指令地址)压入堆栈等数据结构进行保存,一般由程序员在编写程序时通过调用指令和相应的返回指令配合来确保返回地址的正确处理;而中断服务程序的返回地址是由处理器自动保存的,处理器在响应中断时会将当前程序计数器的值以及其他相关寄存器状态等关键信息按照特定的机制保存起来(如压入系统定义的特定堆栈区域),在中断服务程序执行完毕后,再依据这些保存的信息准确地返回原来被中断的程序继续执行,无需程序员手动干预。
- 执行环境不同:子程序执行时是在主程序的执行环境下,共享主程序的一些资源(如寄存器等),当然也可以根据需要进行局部变量等的定义和处理;而中断服务程序有相对独立的执行环境,它需要快速、高效地处理中断事件,一般尽量减少对主程序运行环境的影响,并且由于中断的突发性,中断服务程序要考虑到在任何时刻都可能被触发执行,所以对可使用的资源和执行时间等方面都有更严格的限制,例如不能长时间占用某些关键资源,以免影响主程序及其他中断的正常处理。
③ 中断使能和禁用的方法(Means to Enable and Disable Interrupt)
- 软件控制方式:通过在程序中使用特定的指令来实现中断的使能和禁用。例如,在一些处理器中,有专门的中断使能指令(如
STI,表示设置中断允许标志位,使中断能够被响应)和中断禁用指令(如CLI,清除中断允许标志位,禁止中断响应),程序员可以根据程序执行的不同阶段和需求,在合适的地方插入这些指令来控制中断的开启和关闭。比如在一段对时间要求严格、不希望被中断打扰的关键代码执行期间,可以使用中断禁用指令关闭中断,等这段代码执行完毕后,再用中断使能指令打开中断,恢复系统对外部中断的响应能力,这种方式简单灵活,但需要程序员准确把握中断控制的时机,否则可能导致系统错过重要的中断事件或者出现其他异常情况。 - 硬件控制方式:有些硬件设备本身带有中断屏蔽功能,通过设置设备上的相关硬件引脚或者寄存器位来控制是否允许该设备产生中断请求。例如,一个定时器芯片可能有一个中断屏蔽引脚,当该引脚接高电平(假设)时,定时器即使时间到了也不会向处理器发送中断请求,只有当引脚接低电平时才允许发送中断,通过这种硬件层面的控制可以对特定设备的中断进行单独管理,方便在系统调试、故障排查或者特定的运行场景下对中断进行精细的控制,避免不必要的中断干扰或者确保关键设备的中断能够及时被处理。
④ 处理多个设备中断(Handling multiple devices interrupt)
- 设备识别(Device identification: Software polling, vectored
interrupt):
- 软件轮询(Software polling):当多个设备可能同时产生中断请求时,软件轮询方式下,处理器在响应中断后,会依次查询各个可能产生中断的设备的状态寄存器,通过读取寄存器中的状态信息来判断是哪个设备触发的中断。例如,系统中有键盘、鼠标、磁盘三个设备可能产生中断,处理器响应中断后,先读取键盘的状态寄存器,看是否有按键相关的中断标志位被设置,如果没有再去读取鼠标的状态寄存器,依次类推,直到找到触发中断的设备,然后执行对应的中断服务程序。这种方式实现简单,但效率较低,因为每次都要逐个查询设备状态,花费的时间较长,特别是当设备数量较多时,会导致中断响应时间增加,影响系统的实时性性能,一般适用于设备数量较少、对中断响应速度要求不高的简单系统。
- 向量中断(Vectored interrupt):向量中断则是一种更高效的设备识别方式,每个中断源都有一个对应的中断向量(通常是一个内存地址或者一个编号等形式),当某个设备产生中断请求并被处理器响应后,设备会直接提供其对应的中断向量给处理器,处理器根据这个中断向量可以快速定位到对应的中断服务程序入口地址,无需像软件轮询那样逐个排查设备。例如,键盘中断对应的中断向量为地址0x1000,磁盘中断对应的中断向量为地址0x2000等,当处理器收到中断请求并确认允许响应后,设备将自己的中断向量发送给处理器,处理器直接跳转到相应地址去执行对应的中断服务程序,大大提高了中断响应速度,广泛应用于现代计算机系统中,尤其在处理多个复杂设备的中断情况时优势明显。
- 中断嵌套(Interrupt nesting):中断嵌套是指在执行一个中断服务程序的过程中,又有更高优先级的中断请求发生,处理器会暂停当前正在执行的中断服务程序,转而去处理这个更高优先级的中断,等处理完更高优先级的中断后,再返回继续执行之前被打断的中断服务程序,就如同在处理一个紧急事务时,又出现了更紧急的事情,先去处理更紧急的事务,然后再回来接着处理原来的事务一样。实现中断嵌套需要处理器能够支持中断优先级的判断以及相应的现场保存和恢复机制,合理设置中断优先级对于保证系统中重要且紧急的中断能够及时得到处理、避免低优先级中断长时间占用处理器资源等方面起着关键作用,例如,实时性要求很高的定时器中断可能被设置为较高优先级,而相对不那么紧急的打印机中断可以设置为较低优先级。
- 处理同时中断请求(Handle simultaneous interrupt request):当多个中断请求同时发生时,处理器首先会根据中断优先级来决定先处理哪个中断。如果中断优先级相同,不同的处理器可能有不同的处理策略,有的会按照固定的顺序(如按照中断请求线的编号顺序等)进行处理,有的可能采用轮流处理等方式。一般来说,处理器会先响应并处理优先级最高的中断请求,执行其对应的中断服务程序,在这个过程中,如果又有新的中断请求且优先级更高,就会发生中断嵌套;如果新的中断请求优先级低于当前正在处理的中断,就会暂时忽略,等当前中断处理完毕后,再根据情况判断是否处理其他中断请求,通过这种方式有序地处理多个同时发生的中断请求,保障系统的稳定运行和对各种事件的及时响应。
4. 直接存储器访问(DMA)的原理(Principle of DMA)
- 基本原理:直接存储器访问(DMA)是一种用于在外部设备和内存之间直接进行高速数据传输的技术,目的是减轻处理器在I/O数据传输过程中的负担,提高数据传输效率。在传统的程序控制I/O或通过中断进行I/O操作时,数据的传输都需要处理器参与,比如从磁盘读取数据到内存,处理器要不断地执行指令来控制磁盘读写、将数据从磁盘端口搬运到内存等操作,而DMA方式下,DMA控制器会接管数据传输的控制权,它可以直接在外部设备(如磁盘、网卡等)和内存之间建立数据通路,按照事先设置好的传输参数(如传输的起始地址、数据长度、传输方向等)自动进行数据传输,无需处理器频繁地介入,处理器在这个过程中可以继续执行其他程序任务,只有在数据传输开始和结束等关键阶段才需要与DMA控制器进行交互,例如,当DMA传输完成后,DMA控制器会向处理器发送一个中断请求,告知处理器数据传输已经结束,此时处理器可以进行后续的数据处理等相关操作。
- 优点与应用场景:优点是能够实现高速的数据传输,特别适用于大量数据快速传输的场景,如磁盘与内存之间的数据读写、网络数据的接收和发送等,大大提高了I/O操作的效率,减轻了处理器在I/O方面的工作量,使处理器能够更专注于执行计算、逻辑处理等核心任务。在现代计算机系统中,凡是涉及到高速、大容量的数据传输操作,基本都会采用DMA技术,比如在多媒体处理中,音频、视频数据在设备与内存之间的传输就经常依赖DMA来快速完成,提升系统整体性能。
5. DMA传输模式(DMA Transfer Modes: Burst Mode, Cycle Stealing Mode, Transparent Mode)
- 突发模式(Burst Mode):
- 原理与特点:在突发模式下,DMA控制器一旦获得总线控制权,就会连续地进行多个数据单元(如字节、字等)的传输,一次性将一批数据快速从源地址(如外部设备的缓存)传输到目标地址(如内存的指定区域),在整个传输过程中一直占用总线资源,直到这批数据传输完毕才释放总线控制权。例如,要从磁盘读取一个较大的数据块到内存,DMA控制器启动突发模式后,会不间断地将磁盘缓存中的数据依次搬运到内存中相应位置,就像开闸放水一样,让数据一股脑地快速传输过去,这种模式传输速度快,但在传输期间会独占总线,可能影响其他设备对总线的使用,导致其他设备在这段时间内无法进行数据传输等操作,所以适用于对传输速度要求极高、且能容忍短时间内总线独占的情况,如高速硬盘的大块数据读写场景。
- 周期窃取模式(Cycle Stealing Mode):
- 原理与特点:周期窃取模式是一种分时复用总线资源的传输方式,DMA控制器在进行数据传输时,每次只占用总线一个或几个时钟周期,利用这些短暂的时间间隙从源地址获取数据并传输到目标地址,然后立即释放总线控制权,让其他设备(包括处理器)可以继续使用总线,等下一个合适的时间间隙再进行下一次数据传输,如此反复,逐步完成整个数据的传输任务。例如,在处理器执行指令的间隙,DMA控制器趁机获取总线控制权,将一个字节的数据从设备传送到内存,然后快速归还总线,它不会长时间独占总线,对其他设备使用总线的影响相对较小,但由于是分散地利用时间间隙进行传输,所以整体传输速度相对突发模式会慢一些,适用于对传输速度有一定要求,同时又需要兼顾其他设备对总线正常使用的场景,如在一些实时性要求不是特别高的I/O设备与内存的数据传输中应用较多。
- 透明模式(Transparent Mode):
- 原理与特点:透明模式下,DMA控制器的操作对处理器和其他设备来说几乎是“透明”的,也就是在数据传输过程中,处理器和其他设备感觉不到DMA的存在,不会因为DMA的数据传输而受到明显干扰。这是因为DMA控制器会利用处理器或其他设备暂时不使用总线的空闲时间来进行数据传输,而且它的操作不会改变处理器等设备对总线的正常访问逻辑和顺序,巧妙地避开了与其他设备的冲突




