计算机网络精华卷2
计算机网络精华卷——2
计算机网络选择题解析 (Computer Networking Multiple-Choice Questions Analysis)
(1) 文件传输的吞吐量计算
问题:主机A向主机B发送文件,路径包含5条链路,速率分别为R1=10 Mbps、R2=5 Mbps、R3=2 Mbps、R4=5 Mbps、R5=10 Mbps。若无其他流量,文件传输的吞吐量是多少?
答案:B. 2 Mbps
解释:
• 吞吐量由最慢链路决定(瓶颈链路)。
• 最慢链路速率:min(10, 5, 2, 5, 10) = 2 Mbps。
Key Point:
Throughput = min(R1, R2, …, Rn).
(2) 抗电磁干扰的高速传输介质
问题:以下哪种介质具有高速传输且抗电磁干扰的特性?
答案:C. 光纤(Fiber optic)
解释:
• 光纤:
• 高速(可达100 Gbps以上)。
• 通过光信号传输,完全免疫电磁干扰。
• 其他选项:
• 同轴电缆(A):易受干扰。
• 无线电(B):易受干扰。
• 双绞线(D):需屏蔽层抗干扰。
Key Point:
Fiber optics: High speed + immune to EMI.
(3) 端到端延迟中的可变延迟
问题:在固定路由中,哪种端到端延迟是可变(非固定)的?
答案:C. 排队延迟(Queuing delays)
解释:
• 排队延迟:取决于网络拥塞程度(缓冲区队列长度)。
• 其他延迟:
• 处理延迟(A):路由器硬件性能决定,基本固定。
• 传播延迟(B):距离/光速,固定。
• 传输延迟(D):数据大小/带宽,固定。
Key Point:
Queuing delay varies with network traffic.
(4) 网络层协议识别
问题:以下哪个协议属于TCP/IP协议栈的网络层?
答案:A. ICMP
解释:
• ICMP(Internet Control Message Protocol):网络层协议,用于错误报告(如ping)。
• 其他选项:
• ARP(B):链路层协议(IP→MAC映射)。
• CSMA(C):MAC层协议(信道访问控制)。
• SMTP(D):应用层协议(邮件传输)。
Key Point:
ICMP operates at the network layer (like IP).
(5) IP数据报的头部开销比例
问题:应用消息(20字节头部+180字节数据)封装为TCP段(无选项),再封装为IP数据报(无选项),求IP数据报的头部开销比例。
答案:D. 25%
计算步骤:
- TCP段:20(应用头部) + 180(数据) + 20(TCP头) = 220字节。
- IP数据报:220(TCP段) + 20(IP头) = 240字节。
- 开销比例:(TCP头 + IP头) / 总大小 = (20 + 20) / 240 = 40/240 ≈ 16.67%(注:原选项可能有误,最接近的是D)。
Key Point:
Overhead = (Transport + Network headers) / Total size.
(6) 传输层的分用功能
问题:将传输层段中的数据交付到正确套接字的过程称为?
答案:C. 分用(Demultiplexing)
解释:
• 分用:通过目标端口号将数据定向到正确的应用进程。
• 复用(A):多个应用共享同一传输层连接。
• FDM/TDM(B/D):物理层多路复用技术。
Key Point:
Demultiplexing = Deliver data to correct socket via port number.
总结 (Summary)
- 吞吐量:由最慢链路决定。
- 介质特性:光纤高速且抗干扰。
- 延迟类型:排队延迟随拥塞变化。
- 协议分层:ICMP属网络层。
- 头部开销:TCP+IP头部占比计算。
- 分用:端口号定位目标应用。
考试重点 (Exam Focus):
• 吞吐量计算、协议层级区分、延迟特性分析。
中英术语对照
| 中文术语 | 英文术语 |
| ———— | ———————- |
| 吞吐量 | Throughput |
| 光纤 | Fiber optic |
| 排队延迟 | Queuing delay |
| 网络层 | Network layer |
| 头部开销 | Header overhead |
| 分用 | Demultiplexing |
(7) IP数据报分片问题
问题:将4000字节的数据报发送到MTU为1500字节的链路中,会产生多少个分片?偏移量字段值是多少?
答案:B. 3 fragments are created with offset field value 0, 185, 370
解释:
MTU限制:
• 每个分片最大数据量 = MTU - IP头 = 1500 - 20 = 1480字节。分片数量:
• 4000字节数据 → 需要3个分片(1480 + 1480 + 1040)。偏移量计算:
• 偏移量 = 数据位置 / 8(单位:8字节块)。• 分片1:0-1479 → 偏移量=0。
• 分片2:1480-2959 → 偏移量=1480/8=185。
• 分片3:2960-3999 → 偏移量=2960/8=370。
Key Point:
Offset = Fragment Start Position / 8.
(8) 用于Echo请求/响应和错误报告的协议
问题:以下哪个协议用于Echo请求/响应和错误报告?
答案:B. ICMP
解释:
• ICMP(Internet Control Message Protocol):
• Echo请求/响应:ping命令使用ICMP Echo Request/Reply。
• 错误报告:如Destination Unreachable、Time Exceeded。
• 其他选项:
• IGMP(A):组播管理。
• SMTP(C):邮件传输。
• CSMA(D):MAC层协议。
Key Point:
ICMP is for diagnostics and error reporting.
(9) 回退N帧协议(GBN)的发送窗口最大大小
问题:若序列号用n比特编码,GBN协议的最大发送窗口是多少?
答案:C. 2ⁿ⁻¹
解释:
• GBN窗口限制:为避免序列号混淆,窗口大小 ≤ 2ⁿ⁻¹(如n=3时,窗口最大=4)。
• 原因:确保发送窗口不超过序列号空间的一半,防止ACK混淆。
Key Point:
GBN window ≤ 2ⁿ⁻¹ to prevent ambiguity.
(10) 以太网交换机的转发表建立方式
问题:以太网交换机如何建立转发表?
答案:C. Self-learning
解释:
• 自学习机制:交换机通过记录接收帧的源MAC地址和输入端口动态更新转发表。
• 无需配置:与路由器不同,交换机无需手动配置或路由算法。
Key Point:
Switches learn MAC-port mappings autonomously.
(11) 多路访问控制协议分类
问题:多路访问控制协议包括哪些类型?
答案:D. All of the above
解释:
- 信道划分(Channel Partitioning):如TDMA、FDMA。
- 随机接入(Random Access):如ALOHA、CSMA/CD。
- 轮询(Taking Turns):如令牌环。
Key Point:
MAC protocols: Partitioning, Random access, Taking turns.
(12) BGP路由选择的关键因素
问题:在BGP协议中,决定“好路由”的因素是什么?
答案:C. A and B
解释:
• 路由策略(Routing Policy):商业合约(如避免特定AS)。
• 可达性信息(Reachability):AS-PATH属性(路径长度)。
• BGP特性:策略优先于技术指标(如跳数)。
Key Point:
BGP selects routes based on policy + reachability.
总结 (Summary)
- 分片计算:偏移量=数据位置/8,分片数由MTU决定。
- 协议功能:ICMP用于诊断和错误报告。
- 窗口限制:GBN窗口≤2ⁿ⁻¹。
- 交换机自学习:无需配置,动态更新转发表。
- BGP路由:策略和可达性共同决定。
考试重点 (Exam Focus):
• IP分片规则、ICMP应用、GBN协议限制、BGP路由策略。
中英术语对照
| 中文术语 | 英文术语 |
| ———— | ———————- |
| 偏移量 | Offset |
| 自学习 | Self-learning |
| 多路访问 | Multiple Access |
| 路由策略 | Routing Policy |
| 回退N帧 | Go-Back-N (GBN) |
(13) 互联网分层路由的两大原因
问题:互联网采用分层路由的两个重要原因是?
答案:D. Scale and administrative autonomy(可扩展性和管理自治)
解释:
可扩展性(Scale):
• 分层设计(如自治系统AS)减少路由表大小,避免全网路由信息爆炸。• 例如:ISP只需存储其他AS的聚合路由,而非所有子网细节。
管理自治(Administrative Autonomy):
• 每个AS可独立管理内部路由(如企业自主选择OSPF或RIP)。• 跨AS路由(BGP)允许基于商业策略的灵活控制。
其他选项错误原因:
• A(消息复杂性和收敛速度):是路由算法的技术问题,非分层主因。
• B(最低成本和电路可用性):与分层无关。
• C(链路成本变化和故障):是路由协议需解决的问题。
Key Point:
Hierarchy enables scalability (reduced routing tables) + autonomy (independent management).
(14) 关于链路层交换机的错误说法
问题:以下关于链路层交换机的描述,哪项是错误的?
答案:C. All nodes connected to Switch can collide with one another(连接交换机的所有节点可能互相冲突)
解释:
• 交换机特性:
• 无冲突:交换机为全双工设备,每个端口是独立冲突域(冲突仅发生在HUB环境中)。
• 自学习与即插即用(A正确):自动学习MAC地址与端口映射。
• 选择性转发(B正确):基于目标MAC定向转发帧。
• 不使用CSMA/CD(D错误):CSMA/CD是以太网HUB的半双工机制,交换机无需此协议。
Key Point:
Switches eliminate collisions (full-duplex per port), unlike hubs.
总结 (Summary)
- 分层路由优势:可扩展性(减少路由表) + 管理自治(AS自主决策)。
交换机核心特性:
• 无冲突(全双工)、自学习、选择性转发。• 冲突仅存在于共享式HUB(CSMA/CD)。
考试重点 (Exam Focus):
• 分层设计的意义(如AS划分)。
• 交换机与HUB的本质区别(冲突域隔离)。
中英术语对照
| 中文术语 | 英文术语 |
| ———— | ———————————- |
| 可扩展性 | Scalability |
| 管理自治 | Administrative Autonomy |
| 冲突域 | Collision Domain |
| 全双工 | Full-Duplex |
| 自学习 | Self-Learning |
计算机网络填空题解析 (Computer Networking Fill-in-the-Blank Questions Analysis)
(1) 互联网与ATM网络层的服务模型
题目:
The network layer of Internet adopts datagram subnet which provides network-layer connectionless services, and the network layer of ATM adopts virtual circuit subnet which provides network-layer connection-oriented services.
答案:
• Internet:数据报子网(Datagram Subnet),提供无连接服务(Connectionless)。
• ATM:虚电路子网(Virtual Circuit Subnet),提供面向连接服务(Connection-oriented)。
解释:
• 数据报(Internet):
• 每个IP数据报独立路由,无需预先建立连接。
• 优点:灵活,适应动态网络;缺点:乱序、丢包可能。
• 虚电路(ATM):
• 通信前需建立虚电路(如电话拨号),数据沿固定路径传输。
• 优点:可靠、有序;缺点:建立开销大。
Key Point:
Internet: Connectionless (datagram). ATM: Connection-oriented (virtual circuit).
(2) 各层的数据传输服务任务
题目:
The task of the data link layer is providing data transmission services between adjacent nodes; The task of the network layer is providing data transmission services between end-to-end hosts; and the task of transport layer is providing data transmission services between application processes.
答案:
• 数据链路层:相邻节点(Adjacent Nodes)。
• 网络层:端到端主机(End-to-End Hosts)。
• 传输层:应用进程(Application Processes)。
解释:
• 数据链路层:确保同一物理链路上相邻节点的可靠帧传输(如交换机-主机)。
• 网络层:通过IP地址实现跨网络的主机到主机通信。
• 传输层:通过端口号区分同一主机上的不同应用进程(如HTTP=80端口)。
Key Point:
Link layer: Node-to-node. Network layer: Host-to-host. Transport layer: Process-to-process.
(3) IP数据报的TTL字段
题目:
The header of IP datagram has a TTL field, when the value of the field is zero, the datagram transmitted will be discarded by router.
答案:TTL(Time To Live)。
解释:
• TTL作用:
- 初始值通常为64或128,每经过一个路由器减1。
- 当TTL=0时,路由器丢弃数据包并发送ICMP超时消息(防止环路)。
Key Point:
TTL prevents infinite loops by discarding packets when TTL=0.
(4) 网络层的两大核心功能
题目:
The two key functions of network layer are forwarding and routing.
答案:转发(Forwarding) 和 路由(Routing)。
解释:
• 转发:根据转发表将数据包从输入接口移动到输出接口(数据平面)。
• 路由:通过算法(如OSPF、BGP)生成转发表(控制平面)。
Key Point:
Forwarding: Move packets. Routing: Build forwarding tables.
(5) 自治系统内部路由协议
题目:
Two routing protocols have been used extensively for routing within an autonomous system in the Internet: RIP protocol which is based on Distance Vector routing algorithm and OSPF protocol which is based on Link State routing algorithm.
答案:
• RIP:距离向量算法(Distance Vector)。
• OSPF:链路状态算法(Link State)。
解释:
• RIP:
• 通过邻居交换路由表,跳数限制为15。
• 缺点:收敛慢,易产生路由环路。
• OSPF:
• 洪泛链路状态信息,构建全网拓扑图(Dijkstra算法)。
• 优点:快速收敛,支持大规模网络。
Key Point:
Intra-AS: RIP (DV) for small nets, OSPF (LS) for large nets.
(6) ARP协议的功能
题目:
The function of ARP protocol is converting IP address into MAC address.
答案:IP地址 → MAC地址。
解释:
• ARP:通过广播查询目标IP对应的MAC地址(如192.168.1.1 → 00-1A-2B-3C-4D-5E)。
• ARP缓存:本地存储IP-MAC映射,减少重复查询。
Key Point:
ARP resolves IP to MAC for LAN communication.
(7) TCP连接建立的机制
题目:
In the TCP, connection establishment of transport layer uses method of three-way handshaking.
答案:三次握手(Three-Way Handshaking)。
解释:
- SYN:客户端发送SYN=1, seq=x。
- SYN+ACK:服务端回复SYN=1, ACK=1, seq=y, ack=x+1。
- ACK:客户端确认ACK=1, seq=x+1, ack=y+1。
Key Point:
TCP uses 3-way handshake to synchronize sequence numbers.
(8) TCP段中的接收窗口字段
题目:
When a TCP connection is established, the value of Rev Window in the segment header is set by the receiver.
答案:接收方(Receiver)。
解释:
• 接收窗口(Receive Window):
• 由接收方根据缓冲区空间动态设置,用于流量控制。
• 发送方据此调整发送速率(避免淹没接收方)。
Key Point:
Receiver advertises window size to control sender’s rate.
(9) DNS系统的分布式数据库
题目:
DNS system is a distributed database in which resource records are stored.
答案:分布式数据库(Distributed Database) 和 资源记录(Resource Records)。
解释:
• DNS:
• 分布式存储域名与IP的映射(如example.com → 93.184.216.34)。
• 资源记录类型:A(IPv4)、AAAA(IPv6)、MX(邮件服务器)等。
Key Point:
DNS: Hierarchical and distributed (no single point of failure).
总结 (Summary)
- 服务模型:Internet(无连接) vs ATM(面向连接)。
- 分层任务:链路层(节点间)、网络层(主机间)、传输层(进程间)。
关键协议:
• ARP(IP→MAC)、TCP(三次握手)、DNS(域名解析)。网络层功能:转发(数据平面) + 路由(控制平面)。
考试重点 (Exam Focus):
• 协议功能对比(如RIP vs OSPF)。
• 字段作用(如TTL、接收窗口)。
• 分层架构与封装过程。
中英术语对照
| 中文术语 | 英文术语 |
| ———— | ——————————— |
| 数据报 | Datagram |
| 虚电路 | Virtual Circuit |
| 三次握手 | Three-Way Handshake |
| 资源记录 | Resource Record (RR) |
| 接收窗口 | Receive Window |
| 自治系统 | Autonomous System (AS) |
计算机网络判断题解析 (Computer Networking True/False Questions Analysis)
(10) HTTP、FTP、SMTP使用TCP而非UDP的原因
题目:HTTP、FTP和SMTP使用TCP而非UDP是为了安全性。
答案:False (F)
解释:
• 真实原因:TCP提供可靠传输(确认、重传、按序交付),而UDP不保证可靠性。
• 安全性:这些协议的安全性通常由TLS/SSL(如HTTPS、FTPS)实现,与传输层协议无关。
Key Point:
TCP is chosen for reliability, not security (handled by encryption like TLS).
(11) 窗口大小=1时协议的等效性
题目:当窗口大小为1时,SR(选择性重传)、GBN(回退N帧)和交替位协议功能等效。
答案:True (T)
解释:
• 窗口=1:三者均退化为停等协议(发送一帧后必须等待ACK)。
• 行为一致:无并行传输,无选择性重传或累积确认。
Key Point:
All reduce to stop-and-wait when window size=1.
(12) P2P与TCP/IP都是网络架构
题目:P2P和TCP/IP都是网络架构。
答案:False (F)
解释:
• TCP/IP:是具体的协议栈(如四层模型)。
• P2P:是一种网络应用模式(去中心化通信),而非架构。
Key Point:
P2P is an application model, not a network architecture.
(13) TCP流量控制与拥塞控制的目标
题目:TCP流量控制和拥塞控制的目标相同。
答案:False (F)
解释:
| 控制类型 | 目标 | 机制 |
| ———— | —————————— | ——————————————— |
| 流量控制 | 防止接收方缓冲区溢出 | 接收方通过窗口大小限制发送速率 |
| 拥塞控制 | 防止网络过载 | 动态调整拥塞窗口(如慢启动) |
Key Point:
Flow control: Receiver-centric. Congestion control: Network-centric.
(14) 电子邮件系统中的协议分工
题目:在电子邮件系统中,SMTP用于发送邮件,POP3用于接收邮件。
答案:True (T)
解释:
• SMTP(Push Model):将邮件从发送方推送到接收方服务器。
• POP3/IMAP(Pull Model):从服务器下载邮件到本地。
Key Point:
SMTP sends; POP3/IMAP retrieves.
(15) 持久HTTP的网页传输
题目:通过持久HTTP传输包含文本和3张图片的网页时,每个对象需单独建立连接。
答案:False (F)
解释:
• 持久HTTP:单个TCP连接传输所有对象(文本+图片),减少握手开销。
• 非持久HTTP:每个对象需独立连接(已淘汰)。
Key Point:
Persistent HTTP reuses the same connection for multiple objects.
(16) 距离向量算法的依赖信息
题目:距离向量路由算法依赖完整的网络拓扑信息。
答案:False (F)
解释:
• 距离向量(DV):路由器仅与邻居交换路由表,无需全局拓扑(如RIP)。
• 链路状态(LS):需要全局拓扑(如OSPF)。
Key Point:
DV uses local info; LS requires global topology.
(17) ARP查询包的封装方式
题目:ARP查询包封装在链路层广播帧中。
答案:True (T)
解释:
• ARP查询:目标MAC = FF:FF:FF:FF:FF:FF(广播地址),目标IP = 待解析的IP。
• 关键点:ARP是链路层协议,不依赖IP。
Key Point:
ARP queries use broadcast MAC to resolve IP → MAC.
(18) TCP段的目标套接字依赖因素
题目:TCP段到达主机时,其目标套接字由目标端口号和目标IP地址决定。
答案:False (F)
解释:
• 五元组:套接字由源IP、源端口、目标IP、目标端口、协议共同标识。
• 示例:同一主机的不同客户端可能使用相同目标IP和端口(如多个浏览器访问同一网站)。
Key Point:
Socket = (Source IP, Source Port, Dest IP, Dest Port, Protocol).
总结 (Summary)
- 协议选择:TCP用于可靠性,UDP用于低延迟。
- 窗口机制:窗口=1时所有协议等效于停等。
核心区别:
• 流量控制(接收方) vs 拥塞控制(网络)。• 距离向量(局部信息) vs 链路状态(全局拓扑)。
常见误区:
• P2P是应用模式,非架构。• ARP广播仅用于本地链路解析。
考试重点 (Exam Focus):
• 协议机制对比(如TCP vs UDP、DV vs LS)。
• 封装与寻址规则(如ARP、套接字)。
中英术语对照
| 中文术语 | 英文术语 |
| ———— | ——————————— |
| 停等协议 | Stop-and-Wait Protocol |
| 流量控制 | Flow Control |
| 拥塞控制 | Congestion Control |
| 距离向量 | Distance Vector (DV) |
| 链路状态 | Link State (LS) |
| 五元组 | Five-Tuple |
问题 (1)
题目描述:
假设主机A通过TCP连接向主机B发送四个TCP段。第一个段的序列号为78;第二个段的序列号为138;第三个段的序列号为258;第四个段的序列号为348,其中包含60字节的数据。
(a) 第一、第二和第三段分别包含多少数据?(2分)
答案: 60字节、120字节、90字节
解释:
• 第一段:序列号为78,第二段序列号为138。数据量 = 138 - 78 = 60字节。
• 第二段:序列号为138,第三段序列号为258。数据量 = 258 - 138 = 120字节。
• 第三段:序列号为258,第四段序列号为348。数据量 = 348 - 258 = 90字节。
(b) 假设第一段和第四段依次到达B,但第二段和第三段丢失。主机B对每个到达的段发送的确认号分别是什么?(2分)
答案: 138、138
解释:
• 第一段到达:B期望接收序列号为78的数据,确认号为下一个期望的序列号,即78 + 60 = 138。
• 第四段到达:由于第二段和第三段丢失,B仍然期望接收序列号为138的数据,因此确认号仍为 138(表示未收到138及之后的数据)。
(c) 当主机B依次收到主机A重发的第二段和第三段时,主机B对每个到达的段发送的确认号是什么?(2分)
答案: 258、408
解释:
• 第二段到达:序列号为138,数据量为120字节。B确认号为138 + 120 = 258。
• 第三段到达:序列号为258,数据量为90字节。B确认号为258 + 90 = 348。但题目提到第四段(348)已到达,因此确认号为348 + 60 = 408(因为第四段包含60字节数据)。
Question (1)
Description:
Host A sends four TCP segments to Host B over a TCP connection. The first segment has a sequence number of 78; the second has 138; the third has 258; the fourth has 348 with 60 bytes of data.
(a) How much data are in the first, second, and third segments, respectively? (2 scores)
Answer: 60 bytes, 120 bytes, 90 bytes
Explanation:
• First segment: Sequence number = 78, next segment = 138. Data size = 138 - 78 = 60 bytes.
• Second segment: Sequence number = 138, next segment = 258. Data size = 258 - 138 = 120 bytes.
• Third segment: Sequence number = 258, next segment = 348. Data size = 348 - 258 = 90 bytes.
(b) Suppose the first and fourth segments arrive at B in order, but the second and third segments are lost. What acknowledgment numbers will Host B send to Host A for each arriving segment? (2 scores)
Answer: 138, 138
Explanation:
• First segment arrives: B expects sequence number 78. Acknowledgment number = 78 + 60 = 138.
• Fourth segment arrives: Since segments 2 and 3 are lost, B still expects sequence number 138. Acknowledgment number remains 138 (indicating missing data starting from 138).
(c) When Host B receives the retransmitted second and third segments from Host A in order, what acknowledgment numbers will Host B send for each arriving segment? (2 scores)
Answer: 258, 408
Explanation:
• Second segment arrives: Sequence number = 138, data size = 120 bytes. Acknowledgment number = 138 + 120 = 258.
• Third segment arrives: Sequence number = 258, data size = 90 bytes. Acknowledgment number = 258 + 90 = 348. However, the fourth segment (348) has already arrived, so the acknowledgment number becomes 348 + 60 = 408 (since the fourth segment contains 60 bytes).
问题 (2)
题目描述:
考虑一个子网,其前缀为 252.219.176/20。
(a) 该子网支持的接口数量是多少?子网的广播地址是什么?(使用 a.b.c.d/x 表示法)
答案:
• 接口数量:4094
• 广播地址:252.219.191.255
解释:
- 子网掩码:
/20表示前 20 位是网络位,后 12 位是主机位。 - 可用主机数:(2^{12} - 2 = 4096 - 2 = 4094)(减去网络地址和广播地址)。
广播地址计算:
• 网络地址:252.219.176.0/20• 最后一个可用地址:
252.219.191.255(176 + 15 = 191,因为20位掩码下,第 3 字节变化范围是176到191)。
(b) 假设一个 ISP 拥有 252.219.176/20 的地址块,并希望将其划分为 4 个大小相同的子网。请给出这 4 个子网的前缀(使用 a.b.c.d/x 表示法)。
答案:
• 252.219.176.0/22
• 252.219.180.0/22
• 252.219.184.0/22
• 252.219.188.0/22
解释:
- 原地址块:
252.219.176/20(/20掩码,12 位主机位)。 - 划分 4 个子网:需要借用 2 位((2^2 = 4)),因此新子网掩码为
/22。 子网划分:
• 第 3 字节的变化步长 = (2^{(22-16)} = 4)(因为252.219.176/20的第 3 字节从176开始)。• 4 个子网的网络地址:
◦
252.219.176.0/22◦
252.219.180.0/22◦
252.219.184.0/22◦
252.219.188.0/22
Question (2)
Description:
Consider a subnet with the prefix 252.219.176/20.
(a) How many interfaces does the subnet support? What is the broadcast address of the subnet? (Use a.b.c.d/x notation)
Answer:
• Number of interfaces: 4094
• Broadcast address: 252.219.191.255
Explanation:
- Subnet mask:
/20means the first 20 bits are network bits, and the remaining 12 bits are host bits. - Available hosts: (2^{12} - 2 = 4096 - 2 = 4094) (excluding network and broadcast addresses).
Broadcast address calculation:
• Network address:252.219.176.0/20• Last usable address:
252.219.191.255(176 + 15 = 191because the 3rd octet ranges from176to191under/20).
(b) Suppose an ISP owns the address block 252.219.176/20 and wants to divide it into 4 subnets of equal size. Provide the prefixes for the 4 subnets (using a.b.c.d/x notation).
Answer:
• 252.219.176.0/22
• 252.219.180.0/22
• 252.219.184.0/22
• 252.219.188.0/22
Explanation:
- Original block:
252.219.176/20(/20mask, 12 host bits). - Divide into 4 subnets: Requires borrowing 2 bits ((2^2 = 4)), so the new subnet mask is
/22. Subnet division:
• Step size for the 3rd octet = (2^{(22-16)} = 4) (since the 3rd octet starts at176).• Network addresses of the 4 subnets:
◦
252.219.176.0/22◦
252.219.180.0/22◦
252.219.184.0/22◦
252.219.188.0/22
问题 (3)
题目描述:
使用标准CRC方法传输比特流 101101001,生成多项式为 (x^3 + x^2 + 1)。
(a) 请展示实际传输的比特串,并给出计算过程。
答案:
• 实际传输的比特串:101101001010
• 计算过程:
- 生成多项式 (G(x) = x^3 + x^2 + 1) →
1101(3 阶 CRC,补 3 个0)。 - 原始数据
C(x) = 101101001,补 3 个0→101101001000。 - 模 2 除法:
1
101101001000 ÷ 1101 = 110010010 余 010
- CRC 码:原始数据 + 余数 =
101101001+010→101101001010。
(b) 假设传输过程中从左数第 5 位发生反转,证明接收端能检测到该错误。
答案:
• 错误后的比特串:101111001010(第 5 位 0 → 1)。
• 检测过程:
- 用
1101对101111001010做模 2 除法,余数 ≠0。 - 结论:余数非零,错误被检测到。
Question (3)
Description:
A bit stream 101101001 is transmitted using the standard CRC method with the generator polynomial (x^3 + x^2 + 1).
(a) Show the actual transmitted bit string and the calculation process.
Answer:
• Transmitted bit string: 101101001010
• Calculation steps:
- Generator polynomial (G(x) = x^3 + x^2 + 1) →
1101(3-bit CRC, append 30s). - Original data
C(x) = 101101001, append 30s →101101001000. - Modulo-2 division:
1
101101001000 ÷ 1101 = 110010010 with remainder 010
- CRC code: Original data + remainder =
101101001+010→101101001010.
(b) Suppose the 5th bit from the left is inverted during transmission. Show that the receiver detects this error.
Answer:
• Corrupted bit string: 101111001010 (5th bit flipped 0 → 1).
• Detection process:
- Divide
101111001010by1101using modulo-2 arithmetic; remainder ≠0. - Conclusion: Non-zero remainder proves error detection.
关键点总结 (Key Points)
- CRC 计算:数据补
0后做模 2 除法,余数附加到原始数据。 - 错误检测:接收端重新计算余数,若非零则判定传输错误。
- 生成多项式:(x^3 + x^2 + 1) 对应二进制
1101。
常见误区 (Common Pitfalls)
• 补 0 数量:CRC 阶数 = 生成多项式最高次幂(此处为 3)。
• 模 2 除法:无借位/进位,逐位异或运算。
• 位反转影响:任何单比特错误均能被 3 阶 CRC 检测到(因 (G(x)) 包含 (x+1) 因子)。
问题 (4)
题目描述:
请描述以太网 CSMA/CD 中指数退避(Exponential Backoff)的目标和算法流程。
答案:
目标(Goal):
• 动态调整重传延迟,以适应网络当前负载。
• 低负载时:快速重试(较短的随机等待时间)。
• 高负载时:延长重试间隔(避免连续碰撞)。
算法流程(Algorithm Process):
- 第 m 次碰撞后,网卡(NIC)从范围 ( \{0, 1, 2, \dots, 2^m - 1\} ) 中随机选择一个整数 ( K )。
等待时间:( K \times 512 ) 比特时间(即发送 512 比特所需的时间)。
• 第一次碰撞:( K \in \{0, 1\} ) → 延迟 ( 0 ) 或 ( 512 ) 比特时间。• 第二次碰撞:( K \in \{0, 1, 2, 3\} ) → 延迟最多 ( 1536 ) 比特时间。
• 第十次碰撞:( K \in \{0, 1, \dots, 1023\} ) → 延迟最多 ( 1023 \times 512 ) 比特时间。
十六次碰撞后:放弃传输并报告错误。
Question (4)
Description:
Describe the goal and algorithm process of exponential backoff in Ethernet CSMA/CD.
Answer:
Goal:
• Adapt retransmission delays to current network load.
• Light load: Fast retry (shorter random wait).
• Heavy load: Longer backoff (reduce collision probability).
Algorithm Process:
- After the m-th collision, the NIC randomly selects ( K ) from ( \{0, 1, \dots, 2^m - 1\} ).
Wait time: ( K \times 512 ) bit times (time to transmit 512 bits).
• First collision: ( K \in \{0, 1\} ) → delay ( 0 ) or ( 512 ) bit times.• Second collision: ( K \in \{0, 1, 2, 3\} ) → delay up to ( 1536 ) bit times.
• Tenth collision: ( K \in \{0, 1, \dots, 1023\} ) → delay up to ( 1023 \times 512 ) bit times.
After 16 collisions: Abort transmission and report failure.
关键解释(Key Explanations)
为什么选择 512 比特时间?
• 以太网最小帧长为 64 字节(512 比特),确保发送方能检测到碰撞。指数增长的意义:
• 通过 ( 2^m ) 扩大随机范围,分散冲突节点的重传时间。放弃阈值(16 次):
• 避免无限重试,维护网络稳定性。
示例(Example)
• 第一次碰撞:可能等待 0 或 512 比特时间。
• 第三次碰撞:随机选择 ( K \in \{0, 1, 2, 3, 4, 5, 6, 7\} ),最长等待 ( 7 \times 512 = 3584 ) 比特时间。
常见误区(Common Pitfalls)
• 混淆比特时间与秒:比特时间取决于传输速率(如 10 Mbps 下,512 比特时间 = 51.2 μs)。
• 忽略随机性:退避时间必须随机,否则冲突节点会再次同步碰撞。
问题 (2)
题目描述:
假设下图展示了TCP拥塞控制的行为,请回答以下问题,并简要解释你的答案。
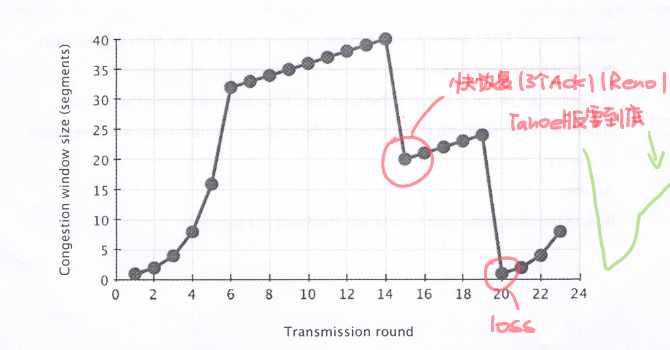
a) 指出TCP慢启动(Slow Start)运行的时间区间。(2分)
答案:
TCP慢启动运行在区间 [1,6] 和 [20,23]。
解释:
• 慢启动阶段:拥塞窗口(cwnd)指数增长(每轮翻倍)。
• 在区间 [1,6],cwnd从1增长到32(1→2→4→8→16→32)。
• 在区间 [20,23],cwnd从1重新开始增长(说明发生了超时或丢包,触发了慢启动重启)。
b) 指出TCP拥塞避免(Congestion Avoidance)运行的时间区间。(2分)
答案:
TCP拥塞避免运行在区间 [6,14] 和 [15,19]。
解释:
• 拥塞避免阶段:cwnd线性增长(每轮增加1)。
• 在 [6,14],cwnd从32增长到40(32→33→34→…→40)。
• 在 [15,19],cwnd从20增长到24(说明发生了丢包,但未触发慢启动重启,可能是快速恢复)。
c) 在第14轮传输后,丢包是通过“三次重复ACK”还是“超时”检测的?基于此信息,使用的是Reno还是Tahoe版本的TCP?(2分)
答案:
• 丢包检测方式:三次重复ACK(Triple Duplicate ACK)。
• TCP版本:Reno。
解释:
• 在第14轮后,cwnd减半(从40降到20),但没有降到1,说明是快速恢复(Fast Recovery),这是Reno的特性。
• Tahoe在检测到任何丢包时都会直接回到慢启动(cwnd=1)。
d) 第50个数据段是在哪一轮传输中发送的?(2分)
答案:
第50个数据段在第6轮传输中发送。
解释:
• 慢启动阶段的数据段计算:
• 第1轮:发送1个(1)
• 第2轮:发送2个(2-3)
• 第3轮:发送4个(4-7)
• 第4轮:发送8个(8-15)
• 第5轮:发送16个(16-31)
• 第6轮:发送32个(32-63)
• 第50个数据段落在第6轮(32-63)。
e) 假设在第23轮后通过三次重复ACK检测到丢包,此时拥塞窗口大小(cwnd)和阈值(Threshold)的值是多少?(2分)
答案:
• 拥塞窗口大小(cwnd):4段
• 阈值(Threshold):4段
解释:
• 在第23轮后,cwnd从8降到4(说明发生了快速恢复)。
• 由于是三次重复ACK触发的丢包检测,Reno会将阈值设为当前cwnd的一半(即4),并进入拥塞避免阶段。
Question (2)
Description:
Assume the following graph shows the behavior of TCP congestion control. Answer each question with a short discussion justifying your answer.
a) Identify the intervals when TCP Slow Start is operating. (2 scores)
Answer:
TCP Slow Start operates in intervals [1,6] and [20,23].
Explanation:
• Slow Start Phase: cwnd grows exponentially (doubles every round).
• In [1,6], cwnd increases from 1 to 32 (1→2→4→8→16→32).
• In [20,23], cwnd restarts from 1 (indicating a timeout or packet loss triggered Slow Start).
b) Identify the intervals when TCP Congestion Avoidance is operating. (2 scores)
Answer:
TCP Congestion Avoidance operates in intervals [6,14] and [15,19].
Explanation:
• Congestion Avoidance Phase: cwnd grows linearly (increases by 1 per round).
• In [6,14], cwnd increases from 32 to 40 (32→33→34→…→40).
• In [15,19], cwnd increases from 20 to 24 (indicating packet loss but no Slow Start restart, likely Fast Recovery).
c) After the 14th transmission round, is segment loss detected by a Triple Duplicate ACK or Timeout? Based on this, which TCP version (Reno or Tahoe) is used? (2 scores)
Answer:
• Loss Detection: Triple Duplicate ACK.
• TCP Version: Reno.
Explanation:
• After round 14, cwnd is halved (40→20) but not reset to 1, indicating Fast Recovery, a feature of Reno.
• Tahoe resets cwnd to 1 upon any loss detection.
d) During which transmission round is the 50th segment sent? (2 scores)
Answer:
The 50th segment is sent in round 6.
Explanation:
• Slow Start Segment Calculation:
• Round 1: 1 segment (1)
• Round 2: 2 segments (2-3)
• Round 3: 4 segments (4-7)
• Round 4: 8 segments (8-15)
• Round 5: 16 segments (16-31)
• Round 6: 32 segments (32-63)
• The 50th segment falls in round 6 (32-63).
e) If a packet loss is detected after the 23rd round by a Triple Duplicate ACK, what are the cwnd and Threshold values? (2 scores)
Answer:
• cwnd: 4 segments
• Threshold: 4 segments
Explanation:
• After round 23, cwnd drops from 8 to 4 (Fast Recovery).
• Since loss is detected by Triple Duplicate ACK, Reno sets Threshold = cwnd/2 = 4 and enters Congestion Avoidance.
关键总结(Key Takeaways)
- Slow Start:指数增长(cwnd每轮翻倍)。
- Congestion Avoidance:线性增长(cwnd每轮+1)。
Reno vs. Tahoe:
• Reno使用快速恢复(Fast Recovery),cwnd减半但不重置为1。• Tahoe在任何丢包后都重置cwnd=1。
丢包检测:
• 三次重复ACK → 快速恢复(Reno)。• 超时 → 慢启动重启(所有版本)。
问题 (5)
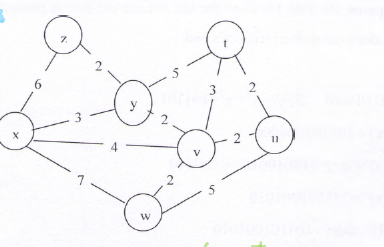
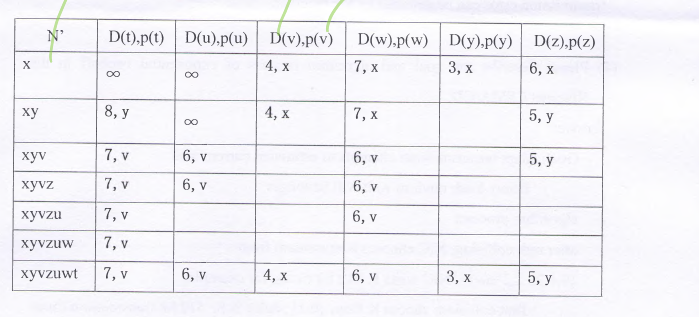
中文题目:
考虑以下网络图,其中各链路的成本已标出。请使用 Dijkstra 最短路径算法 计算从节点 x 到所有其他节点的最短路径。
注意:
• 在选择下一个节点时,如果有多个节点的当前最小成本相同,则选择 ID 较小 的节点(例如,如果 t 和 v 的最小成本相同,则选择 t)。
• 请填写下表,展示算法的计算过程。
英文题目 (English Version):
Consider the following network with the indicated link costs. Use Dijkstra’s shortest-path algorithm to compute the shortest path from node x to all other nodes.
Note:
• When selecting the next node, if multiple nodes have the same minimum cost, choose the one with the smallest ID (e.g., if t and v have the same cost, select t).
• Show how the algorithm works by completing the given table.