
评价类模型
评价类模型
层次分析法
背景:
层次分析法作为一种主观权重设计方法,一般不需要大量的数据,适合应用于那些比较难以用定量方法解决的问题。
是在对复杂的决策问题的本质、影响因素及其内在关系等进行深入分析的基础上,利用较少的定量信息使决策的思维过程数学化,从而为多目标、多准则或无结构特性的复杂决策问题提供简便的决策方法
层次分析法的应用

Matlab 小知识
1 | %% Matlab基本的小常识 |
第一步
建立层次结构模型 简述:
将决策的目标、考虑的因素(决策准则)和决策方案,按它们之间的相互关系分为最高层、中间层和最低层,绘出层次结构图。
最高层:决策的目的、要解决的问题。
中间层:考虑的因素、决策的准则。
最低层:决策时的备选方案。
对于相邻的两层,称高层为目标层,低层为因素层。
如图:


第二步
构造判断矩阵 从层次结构模型的第2层开始,对于从属于(或影响)上一层每个因素的同一层诸因素,构造判断矩阵,直到最下层。
在确定各层次各因素之间的权重时,如果只是定性的结果,则常常不容易被别人接受,因而Saaty等人提出:一致矩阵法,即:
1.不把所有因素放在一起比较,而是两两相互比较。
2.对此时采用相对尺度,以尽可能减少性质不同的诸因素相互比较的困难,以提高准确度。
判断矩阵是表示本层所有因素针对上一层某一个因素的相对重要性的比较。判断矩阵的元素���用Saaty的1-9标度方法给出。
心理学家认为成对比较的因素不宜超过9个,即每层不要超过9个因素。




第三步
计算单层权向量并做一致性检验
能否确认层次单排序,需要进行一致性检验,所谓一致性检验是指对A确定不一致的允许范围。
定理1:n阶一致阵的唯一非零特征根为n
定理2:n阶正互反阵A的最大特征根λ≥n,当且仅当λ=n时A为一致阵



第四步

局限性

代码:
1 | %% 注意:在论文写作中,应该先对判断矩阵进行一致性检验,然后再计算权重,因为只有判断矩阵通过了一致性检验,其权重才是有意义的。 |
例题展示






模糊综合评价模型
核心在于模糊的概念
概述
数学归纳法

数学的量的划分
确定性
不确定性

模糊数学

经典集合和模糊集合的基本概念
经典集合

模糊集合:描述模糊性概念的集合

表示方法


隶属函数的三种确定方法
模糊统计法
用的比较少的模糊统计法
找特别多人

借助已有的客观尺度
合适的指标,并能收集到数据

指派法
有很多分布,主要是梯形分布


例题一

例题二

梯形分布

应用:模糊综合评价

知识点:
确定因素集:相关性之间要不太强
确定评语集:由于每个指标的评价值不同,形成不同的等级。

确定权重:Delphi法,专家法。
无数据:层次分析法
有数据:熵权法
权重也需要归一化,确定的时候注意
模糊综合判断矩阵
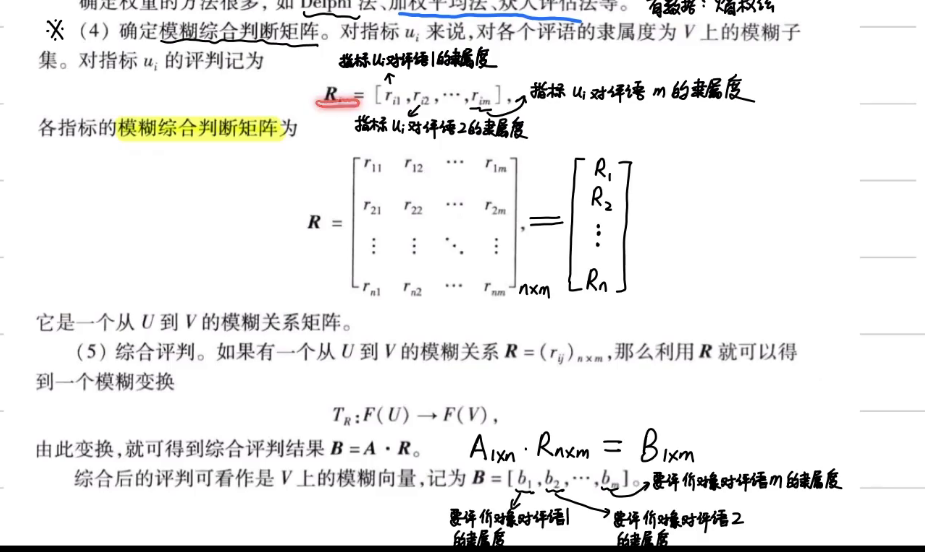

解释:第一列表示各个指标对于评语1的隶属度

例题:

层次分析法得到权重


一级模糊综合评价模型例子
一

SO2的隶属度计算

同理:

AR=
二



多级模糊综合评价模型的引入




重复1的步骤2遍即可
三极模糊综合评价模型

同理



基于熵权法对Topsis模型的修正

找出最优与最最差,比较程度
常用的综合评价方法,充分利用原始数据
指标很多数据已知的评分问题
层次分析不适合指标太多的,都是主观的,没数据
指标的处理(正向化)
效益类
极小类
中间型
区间型
指标的处理

标准化


计算距离与得分

例子:


第一步




第二步

第三步
计算各评价对象与最优方案的贴近程度。正其中
的取值范围为[0,1],越接近1表明样本评分越好。

第四步
进行排序即可
代码
1 | %% 第一步:把数据复制到工作区,并将这个矩阵命名为X |
例题



熵权法新鲜出炉




1 | %% 第一步:把数据复制到工作区,并将这个矩阵命名为X |





