
Algorithm Analysis
Algorithm Analysis
概要
简单计算模型 Simple Model of Computation
Big-Oh 及其他符号的定义 Definitions of Big-Oh and Other Notations
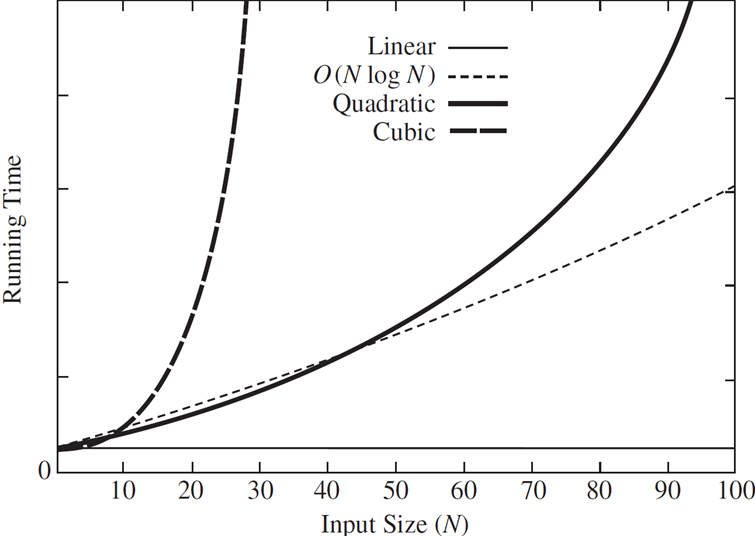
常见函数及其增长率 Common Functions and Growth Rates
最坏情况 vs. 平均情况分析 Worst Case vs. Average Case Analysis
如何进行分析 How to Perform Analyses
比较示例 Comparative Examples
我们如何衡量算法的效率?
A. 在我的电脑上对它进行计时。
B. 将它的运行时间与已经分析过的另一个算法进行比较。
C. 计算它在任意输入数据集上执行的指令数量。
简单计算模型
- 指令按顺序执行
- 具有标准的简单指令集
- 执行加法、乘法、比较和赋值操作每步都只需一个时间单位
- 假设模型使用定长整数(例如 32 位)且没有复杂操作,例如矩阵求逆或排序
- 假设有无限的内存
需要分析的内容
- 运行所需的时间
- 运行程序和存储数据结构所需的内存或磁盘空间
主要因素
- 使用的算法
- 算法的输入
- 不包括编程语言、编译器等……
- 分析的是算法而不是程序
复杂度符号
1. Big-O (大O符号)
- 表示算法的 最坏情况 时间复杂度或空间复杂度的上界。
- 定义: 若存在正常数 \(c\) 和 \(n_0\),使得当 \(N
\geq n_0\) 时,函数 \(T(N) \leq c \cdot
f(N)\),则 \(T(N)\) 是 \(O(f(N))\)。
- 形式化表达:
$ T(N) = O(f(N)) , c, n_0 > 0 T(N) c f(N) N n_0 $
- 形式化表达:
- 作用: 用于分析算法在 最坏情况下 的性能上界,表示增长的速率。
2. Big-Omega (大Ω符号)
- 表示算法的 最优情况 时间复杂度或空间复杂度的下界。
- 定义: 若存在正常数 \(c\) 和 \(n_0\),使得当 \(N
\geq n_0\) 时,函数 \(T(N) \geq c \cdot
g(N)\),则 \(T(N)\) 是 $\(Ω(g(N))\)。
- 形式化表达:
$ T(N) = Ω(g(N)) , c, n_0 > 0 T(N) c g(N) N n_0 $
- 形式化表达:
- 作用: 用于分析算法在 最优情况下 的性能下界。
3. Big-Theta (大Θ符号)
- 表示算法的 平均情况 时间复杂度或空间复杂度的精确界限。
- 定义: 若 \(T(N)\)
同时是 \(O(h(N))\) 和 \(Ω(h(N))\),则 \(T(N)\) 是 \(Θ(h(N))\)。
- 形式化表达:
$ T(N) = Θ(h(N)) T(N) = O(h(N)) T(N) = Ω(h(N)) $
- 形式化表达:
- 作用: 表示算法的复杂度的 准确界限,即它既不会超过某个上界,也不会低于某个下界。
4. Little-o (小o符号)
- 表示算法的复杂度上界,但是相比于 \(Big-O\),提供了一个更严格的上界,没有达到上界。
- 定义: 对于任意正常数 \(c\),都存在 \(n_0\),使得当 \(N
> n_0\) 时,函数 \(T(N) < c \cdot
p(N)\),则 \(T(N)\) 是 \(o(p(N))\)#$。
- 形式化表达:
$ T(N) = o(p(N)) c > 0, , , n_0 > 0 T(N) < c p(N) N > n_0 $
- 形式化表达:
- 作用: 提供算法复杂度的一个严格上界,表示 \(T(N)\) 增长得比 \(p(N)\) 慢。
例子
假设我们有以下算法的运行时间:
- \(T(N) = 5N^2 + 3N +
2\):
- 它的最坏情况时间复杂度为 \(O(N^2)\)。
- 它的最优情况时间复杂度为 \(Ω(N^2)\)。
- 它的平均情况时间复杂度为 \(Θ(N^2)\)。
- 它的运行时间不会严格达到 \(N^3\) 的增长,因此 \(T(N) = o(N^3)\)。
大O符号
定义
- \(T(N) = O(f(N)\)) 表示:如果存在正的常数 \(c\) 和 \(n_0\),使得当 \(N \geq n_0\) 时,满足 \(T(N) \leq c \cdot f(N)\),那么我们称 \(T(N)\) 是 \(O(f(N))\) 的。
- 解释:
- \(T(N)\) 的增长速率与 \(f(N)\) 类似或更慢。
- 我们说“T(N) 的阶是 f(N)” 或者“f(N) 是 T(N) 的上界”。
- \(T(N)\) 的增长速率与 \(f(N)\) 类似或更慢。
简化 T(N)
- 通常我们会尝试将复杂的函数 \(T(N)\) 简化为一个或多个常见的函数形式,例如线性、对数、平方等。
示例 1
- \(T(N) = 3N + 4\):
- 这是一个线性函数。直观上,函数 \(f(N)\) 应该是 \(N\)。
- 更正式地,我们可以推导: \(T(N) = 3N + 4 \leq 3N + 4N, \quad N \geq 1\) \(T(N) \leq 7N, \quad N \geq 1\) 因此,\(T(N)\) 是 \(O(N)\) 的,即 \(T(N)\) 的阶是 \(N\)。
示例 2
- \(T(N) = 30N + 8\):
- 我们同样需要找到常数 \(c\) 和 \(n_0\),使得 \(T(N) \leq c \cdot N\)。
- 推导过程: $ T(N) = 30N + 8 30N + 8N, N $ $ T(N) 38N, N $ 因此,\(T(N)\) 是 \(O(N)\),其中 \(c = 38\),\(n_0 = 1\)。
- Big-O 定义: \(T(N\)) = \(O(f(N))\) 表示函数 \(T(N)\) 的增长速度不超过 \(f(N)\)。
- 常数 \(c\) 和 \(n_0\) 的选择用于表示函数在较大输入 \(N\) 时的表现。
增长速率
增长速率指的是当输入规模增大时,算法的开销增长的速度。
解释:
当我们分析算法时,通常关心的是算法在处理不同规模的数据时,运行时间或资源消耗(如内存)的增长情况。为了量化这种增长,我们使用增长速率来描述算法随着输入大小 \(N\) 增大时,开销的变化。
不同的算法有不同的增长速率,随着输入的增大,有些算法可能增长得非常快,而有些则比较平缓。通过使用诸如大O(\(Big-O\))、大Ω(\(Big-Omega\))和大Θ(\(Big-Theta\))等符号,我们可以对这些增长率进行分类和比较。
例如:
- 线性增长(如 \(O(N)\))意味着每当输入大小增加一倍,算法的运行时间也大约增加一倍。
- 指数增长(如 \(O(2^N)\))意味着当输入稍微增大时,算法的开销就会急剧增加。
这些符号帮助我们在不同的算法之间建立相对顺序,从而决定哪些算法在大规模输入下会更有效。
简化规则
规则 1:
- 如果 \(T_1(N) = O(f(N))\) 且
$T_2(N) = O(g(N)) $,则:
- $ T_1(N) + T_2(N) = O(f(N) + g(N))$
- \(T_1(N) \times T_2(N) = O(f(N) \times g(N))\)
这意味着,若两个函数分别有不同的增长速率,那么它们的加法或乘法可以根据这些增长速率进行组合。
示例:
假设我们有 \(T_1(N) = O(f(N))\) 和 $T_2(N) = O(g(N)) $, 且 \(f(N) = 4N^2 + 6\) 和 \(g(N) = 3N\),要求 $ T(N) = T_1(N) + T_2(N) $。
我们根据规则可以得出:
步骤 1:
\(T(N) = T_1(N) + T_2(N) = O(f(N) + g(N))\)步骤 2:
$T(N) = O(4N^2 + 3N + 6) $步骤 3:
当 \(N\) 很大时,最高阶项 \(4N^2\) 支配增长速率,其他项(如 \(3N\) 和常数 \(6\))可以忽略。因此,最终结果为: $ T(N) = O(N^2) $
简化规则笔记
规则 2:
如果 $ T(N)$ 是一个次数为 $k $ 的多项式,那么:
- \(T(N) = \Theta(N^k)\)
解释: 多项式的增长速率主要取决于最高次项。例如,\(T(N) = 4N^3 + 2N^2 + 5N + 7\),由于 \(N^3\) 是最高次项,因此 \(T(N)\) 的增长速率是 \(\Theta(N^3)\)。一般来说,任何多项式的时间复杂度都是由它的最高阶项决定的。
规则 3:
对于任何常数 $ k $,都有:
- \(\log^k N = O(N)\)
解释: 虽然对数函数增长得很慢,但其上界可以通过线性函数 \(N\) 来表示。即使是 $ ^k N$ 这样的函数,随着 $ N $ 的增大,线性函数 \(N\) 的增长速率最终会超过对数函数。
规则 4(传递性规则):
如果 \(T(n) = O(g(n))\) 且 $ g(n) = O(h(n))$,则:
- \(T(n) = O(h(n))\)
解释: 这是传递性的应用,意思是如果 \(T(n\))$ 可以被某个函数 \(g(n)\) 控制,而 \(g(n)\) 又可以被更快增长的函数 \(h(n)\) 控制,那么我们可以直接认为 \(T(n)\) 受 \(h(n)\) 控制。
规则 5(忽略常数规则):
如果 $T(n) = O(k g(n)) $(其中 $ k > 0 $ 是常数),则:
- $ T(n) = O(g(n)) $
解释: 这条规则表明,我们在分析复杂度时,可以忽略常数因子。即便一个函数被一个常数 \(k\) 缩放,它的增长速率依旧是由 \(g(n)\) 决定的,常数因子不会改变函数的渐近复杂度。例如,$ 5N$ 的增长速率和 $ N $ 是相同的。
如何分析算法
渐近算法分析:
- 渐近分析用于衡量算法的效率,尤其是当输入规模变大时,算法的增长速率。
- 渐近分析是算法复杂度的主要工具,帮助我们预测其在大输入规模下的表现。
几种常见的情况:
1. 最优情况 (Best-Case):
- 描述算法在最佳输入条件下的性能。
- 一般来说,最优情况的分析对现实应用的指导意义较小,因为通常难以保证所有输入都是最优的。
2. 平均情况 (Average-Case):
- 典型的输入条件下,算法的性能。
- 反映了算法的实际表现,通常是更重要的分析目标。
- 需要了解输入数据的分布,才能做出准确的平均情况分析。不同的输入分布会导致不同的平均时间复杂度。
3. 最坏情况 (Worst-Case):
- 描述算法在最差输入条件下的性能。
- 尽管最坏情况在实践中不常发生,但它提供了对算法在任何输入上的性能保证。
- 最坏情况分析常用来确保算法在任何情况下都不会有极端糟糕的表现。
关键点:
增长速率: 渐近分析的核心是了解当输入规模 \(N\) 增大时,算法的执行时间或空间需求如何增长。常用的复杂度表示包括 \(O(N)\)、\(O(N^2)\)、\(O(\log N)\) 等。
最优 vs 平均 vs 最坏:
- 最优情况:关注最佳输入下的执行时间,但通常用处不大。
- 平均情况:更贴近实际表现,但需要对输入数据的分布有足够的了解。
- 最坏情况:尽管少见,但提供了对所有可能输入的性能保证。
顺序搜索算法分析
顺序搜索(Sequential Search)是一种基本的查找算法,用于在给定的数组中寻找特定的值。其核心思想是从数组的第一个元素开始,逐一检查每个元素,直到找到目标值或遍历完整个数组。
Q1: 寻找特定值 \(K\) 的成本分析
1. 最佳情况 (Best Case):
- 情况: 当要查找的值 \(K\) 是数组中的第一个元素。
- 检查次数: 只需检查1个值。
- 时间复杂度: \(O(1)\)
2. 最坏情况 (Worst Case):
- 情况: 当要查找的值 \(K\) 是数组中的最后一个元素,或数组中没有值 \(K\)。
- 检查次数: 需要检查所有 \(n\) 个值。
- 时间复杂度: \(O(n)\)
3. 平均情况 (Average Case):
- 情况: 如果在多个不同输入上多次执行顺序搜索。
- 检查次数: 理论上,假设 \(K\) 在数组中均匀分布,平均需要检查 \(\frac{n + 1}{2}\) 个值。
- 时间复杂度: \(O(n)\)
Q2: 寻找最大值的成本分析
分析:
- 无论输入数组是什么情况,寻找数组中最大的值都需要遍历整个数组。
- 检查次数: 每个元素都需要被检查一次,因此总是需要进行 \(n\) 次检查。
- 时间复杂度: \(O(n)\)
复杂度分许例题
循环算法的时间复杂度分析
算法代码
1 | int sumit(int v[], int num) { |
时间复杂度分析
我们将分析此算法的时间复杂度 \(T(num)\)。
- 初始化操作:
int sum = 0;需要常数时间 \(c_1\)。
- 循环操作:
- 循环语句
for (int i = 0; i < num; i++)将会执行 \(num\) 次,每次循环的操作如下:sum = sum + v[i];需要常数时间 \(c_2\)。
- 因此,循环体内部的总时间为 \(c_2 \times num\)。
- 循环语句
- 返回操作:
return sum;需要常数时间 \(c_3\)。
总时间复杂度
将上述部分合并,我们可以得到总的时间复杂度:
$ T(num) = c_1 + (c_2 num) + c_3 $
为了方便计算,我们将常数部分整理如下:
$ T(num) = (c_2) num + (c_1 + c_3) $
我们可以引入常数 \(k_1\) 和 \(k_2\) 使其表述为:
$ T(num) = k_1 num + k_2 $
其中 \(k_1 = c_2\) 和 \(k_2 = c_1 + c_3\)。
大 O 表示法
根据大 O 表示法,我们可以将这个算法的时间复杂度简化为:
$ T(num) = O(num) $
这表示算法的时间复杂度是线性的。
嵌套循环算法的时间复杂度分析
算法代码
1 | int sum(int n) { |
时间复杂度分析
我们将分析此算法的时间复杂度 \(T(n)\)。
- 初始化操作:
int sum = 0;需要常数时间 \(c_1\)。
- 外层循环:
- 外层循环
for (i = 1; i <= n; i++)将执行 \(n\) 次。
- 外层循环
- 内层循环:
- 对于每次外层循环的迭代,内层循环
for (j = 1; j <= n; j++)也将执行 \(n\) 次。 - 因此,内层循环的总执行次数为 \(n\) 次外层循环 × \(n\) 次内层循环 = \(n^2\) 次。
- 对于每次外层循环的迭代,内层循环
- 累加操作:
sum++;是内层循环的主要操作,每次执行需要常数时间 \(c_2\)。
总时间复杂度
将上述部分合并,我们可以得到总的时间复杂度:
$ T(n) = c_1 + (c_2 n^2) + c_3 n $
考虑到常数项,我们将时间复杂度整理为:
$ T(n) = c_1 + c_3 n + c_2 n^2 $
其中,\(c_1\) 是初始化的时间,\(c_3\) 是外层循环的时间,\(c_2\) 是内层循环执行的时间。
大 O 表示法
由于 \(n^2\) 是该表达式中最高次项,因此我们可以将算法的时间复杂度简化为:
$ T(n) = O(n^2) $
这表示算法的时间复杂度是平方级别的。
嵌套循环的时间复杂度分析
算法代码
1 | sum = 0; // 初始化 sum |
时间复杂度分析
- 外层循环:
- 外层循环的条件是
k <= n,并且每次迭代后 \(k\) 都乘以 2。 - 这意味着 \(k\) 的取值将是 \(1, 2, 4, 8, \ldots\),直到 \(k\) 超过 \(n\)。
- 因此,外层循环执行的次数为 \(\log_2(n) + 1\) 次(最后一次的乘法使得 \(k\) 超过 \(n\))。
- 外层循环的条件是
- 内层循环:
- 内层循环的条件是
j <= n,这个循环会执行 \(n\) 次。 - 每次外层循环的迭代,内层循环都会完整执行 \(n\) 次。
- 内层循环的条件是
总时间复杂度
将外层循环和内层循环的执行次数结合起来,我们可以计算总的时间复杂度:
$ T(n) = $
即:
$ T(n) = (_2(n) + 1) n $
简化后,我们可以得到:
$ T(n) = n _2(n) + n $
大 O 表示法
在分析算法的时间复杂度时,我们通常只考虑最高次项,因此可以忽略常数项和低次项。最终,我们可以将算法的时间复杂度表示为:
$ T(n) = O(n n) $
这表示算法的时间复杂度为 \(n \log n\),这是一个较为常见且高效的复杂度级别。
双重循环的时间复杂度分析
算法代码
1 | sum = 0; // 初始化 sum |
时间复杂度分析
- 外层循环:
- 外层循环的条件是
k <= n,并且每次迭代后 \(k\) 都乘以 2。 - 这意味着 \(k\) 的取值将是 \(1, 2, 4, 8, \ldots\),直到 \(k\) 超过 \(n\)。
- 因此,外层循环执行的次数为 \(\log_2(n) + 1\) 次(最后一次的乘法使得 \(k\) 超过 \(n\))。
- 外层循环的条件是
- 内层循环:
- 内层循环的条件是
j <= k,这个循环会根据当前的 \(k\) 值执行 \(k\) 次。 - 在每次外层循环的迭代中,内层循环执行的次数是动态变化的,随着 \(k\) 的增大而增大。
- 内层循环的条件是
总时间复杂度
为了计算总的时间复杂度,我们可以将内层循环的执行次数与外层循环的次数结合起来进行分析。
- 当 \(k = 1\) 时,内层循环执行 1 次。
- 当 \(k = 2\) 时,内层循环执行 2 次。
- 当 \(k = 4\) 时,内层循环执行 4 次。
- 当 \(k = 8\) 时,内层循环执行 8 次。
- ...
- 当 \(k = 2^m\)(其中 \(m\) 为外层循环的当前迭代次数)时,内层循环执行 \(2^m\) 次,直到 \(k\) 超过 \(n\)。
可以看到,在每次外层循环的迭代中,内层循环的总执行次数可以表示为:
$ T(n) = 1 + 2 + 4 + 8 + + k $
求和公式
该和可以用等比数列求和公式计算:
$ T(n) = 2^0 + 2^1 + 2^2 + + 2^m = 2^{m+1} - 1 $
其中 \(m\) 是 \(k\) 使得 \(k \leq n\) 的最大值,因此 \(m \approx \log_2(n)\)。即:
$ T(n) ^{_2(n) + 1} - 1 = 2n - 1 $
大 O 表示法
在算法复杂度分析中,我们通常只关注最高次项,因此可以忽略常数项和低次项。最终,我们可以将算法的时间复杂度表示为:
$ T(n) = O(n) $
时间复杂度分析:双重循环与排序
算法代码
1 | // 假设数组 A 包含 n 个值, |
时间复杂度分析
- 内层循环:
- 内层循环
for (j = 0; j < n; j++)的执行次数是 \(n\) 次。 - 在每次迭代中,调用
random(n)函数,假设该函数的时间复杂度是 \(O(c_1)\),即一个常数时间操作。 - 因此,内层循环的总时间复杂度为: $ T_{} = n O(c_1) = O(n) $
- 内层循环
- 排序操作:
- 在每次外层循环中,调用
sort(A, n)函数,该函数的时间复杂度为 \(O(c_n \log n)\)。 - 因此,排序的时间复杂度是: $ T_{} = O(c_n n) $
- 在每次外层循环中,调用
- 外层循环:
- 外层循环
for (i = 0; i < n; i++)执行 \(n\) 次。 - 每次外层循环都需要执行内层循环和排序操作,因此总的时间复杂度为: $ T(n) = n O(c_1) + n O(c_n n) $
- 合并后得到: $ T(n) = O(n c_1) + O(n c_n n) = O(n + n n) = O(n n) $
- 外层循环
综合分析
由于内层循环的复杂度为 \(O(n)\),而排序的复杂度为 \(O(n \log n)\),对于 \(n\) 趋近于无穷大时,\(n \log n\) 的增长速度要快于 \(n\)。因此,整个代码的时间复杂度由较高的排序操作主导。
总结
- 整体的时间复杂度可以表示为: $ T(n) = O(n(c_1 + c_n n)) = O(n^2 n) $
Θ 表示法
在分析中,实际上,我们考虑的是平均情况复杂度,因此可以将其简化为: $ (n^2 n) $
这表示算法在输入规模为 \(n\) 时的复杂度,包含了随机数生成和排序的平均执行时间。
时间复杂度分析:双重循环与随机排列
下面是对给定代码的时间复杂度分析,包括其在平均情况下的复杂度估计。
算法代码
1 | // 假设 A[] 包含从 0 到 n-1 的随机排列 |
时间复杂度分析
- 外层循环:
- 外层循环
for (i = 0; i < n; i++)执行 \(n\) 次。
- 外层循环
- 内层循环:
- 内层循环
for (j = 0; A[j] != i; j++)的执行次数取决于数组A[]中的元素。由于A[]是从 0 到 \(n-1\) 的随机排列,A[j]等于 \(i\) 的位置是随机的。 - 对于每个 \(i\),内层循环在最坏情况下可能会遍历整个数组 \(A[]\),但是在平均情况下,我们可以通过以下方式计算内层循环的平均执行次数。
- 内层循环
- 平均情况:
- 在随机排列中,值 \(i\) 在数组
A[]中的预期位置是 $ $。因此,平均情况下,内层循环执行的次数约为 $ $。 - 具体来说,内层循环的执行次数可以用以下求和表示: $ = _{i=0}^{n-1} $
- 设内层循环的期望执行次数为 \(E[j] = \frac{0 + 1 + 2 + \ldots + (n-1)}{n} = \frac{(n-1)}{2}\)。
- 因此,内层循环的总时间复杂度为: $ T_{} = n E[j] = n = $
- 在随机排列中,值 \(i\) 在数组
- 整体复杂度:
- 综合内外层循环的复杂度,整体的时间复杂度为: $ T(n) = () = (n^2) $
总结
- 整体的时间复杂度可以表示为: $ T(n) = (n^2) $
这表示在输入规模为 \(n\) 时的复杂度,尤其是对于随机排列的情况。
最终结论
在给定的算法中,由于内层循环的执行次数在平均情况下约为 $ $,最终导致整体的时间复杂度为 $ (n^2) $,反映了该算法在处理随机排列时的效率表现。
杂项
控制结构与时间复杂度分析
在算法分析中,不同的控制结构会对时间复杂度产生不同的影响。以下是对于while循环、if-then-else语句、switch语句、子例程调用和递归子例程的时间复杂度分析的详细笔记。
1. While 循环
- 定义:
while循环是一种控制结构,允许重复执行一段代码,直到条件不满足。 - 时间复杂度:
- 类似于
for循环,while循环的时间复杂度取决于循环的迭代次数。 - 如果循环体的复杂度为 \(O(f(n))\),并且循环运行了 \(k\) 次,则总复杂度为 \(O(k \cdot f(n))\)。
- 类似于
2. If-Then-Else 语句
- 定义: 条件语句,根据条件的真或假来选择执行不同的代码块。
- 时间复杂度:
- 时间复杂度由两个分支中的较大者决定。
- 如果
then分支的时间复杂度为 \(O(f(n))\),else分支的时间复杂度为 \(O(g(n))\),那么: $ T(n) = O((f(n), g(n))) $
3. Switch 语句
- 定义: 一种多分支控制结构,用于根据变量的值执行不同的代码块。
- 时间复杂度:
- 在多分支中,时间复杂度由最耗时的分支决定。
- 如果某个分支的复杂度为 \(O(h(n))\),则总时间复杂度为: $ T(n) = O(h(n)) $
- 需要注意的是,
switch语句的时间复杂度可能受到选择条件的影响。
4. 子例程调用
- 定义: 一段封装好的代码,可以被其他代码调用。
- 时间复杂度:
- 子例程的时间复杂度需要被加到主程序的时间复杂度中。
- 如果主程序的时间复杂度为 \(O(f(n))\),而子例程的时间复杂度为 \(O(g(n))\),则总时间复杂度为: $ T(n) = O(f(n)) + O(g(n)) = O(f(n) + g(n)) $
5. 递归子例程
- 定义: 一个函数在其定义中调用自身。
- 时间复杂度:
- 递归的时间复杂度通常通过递归关系来表达。
- 例如,如果一个递归函数的复杂度可以用关系 \(T(n) = a \cdot T(n/b) + f(n)\) 表示,其中 \(a\) 是递归调用的次数,\(b\) 是输入规模的缩减因子,\(f(n)\) 是非递归部分的复杂度。
- 使用主定理 (Master Theorem) 或其他方法可以找到这个递归关系的闭式解。
递归字符串拼接算法的时间复杂度分析
算法描述
以下是算法的代码片段,该算法通过递归构建一个包含数字的字符串,格式为(n)(n-1)...(1):
1 | // 这里 || 是字符串连接操作符 |
时间复杂度分析
为了分析该算法的时间复杂度,我们可以建立一个递归关系。
- 递归关系:
- 对于 \(n > 1\),算法的时间复杂度 \(T(n)\) 可以表示为: $ T(n) = T(n-1) + c $ 这里,\(c\) 是在递归调用之外执行的常数时间(例如字符串拼接和连接操作)。
- 基础情况:
- 当 \(n = 1\) 时,时间复杂度为常数: $ T(1) = c_1 $
- 展开递归关系:
- 将递归关系逐步展开: $ T(n) = T(n-1) + c $ $ = (T(n-2) + c) + c $ $ = T(n-2) + 2c $ $ = ... $ $ = T(1) + (n-1) c $
- 替换基础情况:
- 替换 \(T(1)\) 的值: $ T(n) = c_1 + (n-1) c $
- 简化表达式:
- 可以将 \(T(n)\) 表达为: $ T(n) = c (n-1) + c_1 $
时间复杂度的结论
从上述推导中,我们可以看到:
- 该算法的时间复杂度是线性的,因为它随着输入大小 \(n\) 的增加而线性增长。
- 最终得出: $ T(n) = Θ(n) $
多个参数的算法分析:像素排序
在本节中,我们将分析一个处理图像的算法,目的是根据像素的颜色数量对颜色进行排序。该算法涉及多个参数:像素数量 \(P\) 和颜色种类 \(C\)。
问题描述
给定一幅具有 \(P\) 个像素的图像,每个像素可以取 \(C\) 种颜色值。我们的目标是对颜色进行排序,排序的依据是每种颜色所占像素的数量。
算法步骤
初始化计数数组:
1
2for (i=0; i<C; i++) // 初始化计数
count[i] = 0;遍历所有像素并计算颜色出现的次数:
1
2for (i=0; i<P; i++) // 查看所有像素
count[value(i)]++; // 增加计数对计数数组进行排序:
1
sort(count); // 排序像素计数
时间复杂度分析
- 初始化计数数组:
- 复杂度为 \(Θ(C)\),因为需要对每个颜色进行一次初始化。
- 遍历所有像素:
- 复杂度为 \(Θ(P)\),因为需要查看每个像素并更新相应颜色的计数。
- 排序计数数组:
- 复杂度为 \(Θ(C \log C)\),这是由于对计数数组的排序操作。
总体时间复杂度
综合以上三步,算法的总时间复杂度可以表示为: $ Θ(C) + Θ(P) + Θ(C C) = Θ(P + C C) $
是否可以忽略 \(Θ(P)\) 或 \(Θ(C \log C)\)?
在考虑是否可以忽略某一部分的时间复杂度时,我们需要比较 \(P\) 和 \(C \log C\) 的大小关系:
- 情况一:如果 \(C\) 远小于
\(P\)
- 当 \(P\) 显著大于 \(C \log C\) 时,即使 \(C\) 增加,\(C \log C\) 的增长速度也不会超过 \(P\)。此时,我们可以近似认为: $ Θ(P + C C) Θ(P) $
- 情况二:如果 \(C\) 远大于
\(P\)
- 如果 \(C\) 显著大于 \(P\),那么 \(C \log C\) 可能会占主导地位。在这种情况下,时间复杂度可能会近似为: $ Θ(P + C C) Θ(C C) $
结论
- 如果 \(P\) 的数量级显著大于 \(C \log C\),则可以忽略 \(Θ(C \log C)\)。
- 反之,如果 \(C\) 较大,则可以忽略 \(Θ(P)\)。
总之,具体能否忽略某一部分时间复杂度需要根据 \(P\) 和 \(C\) 的具体关系来决定。在实际应用中,通常需要考虑 \(P\) 和 \(C\) 的实际值以确定时间复杂度的主导项。
最佳、最坏和平均情况 vs. 上界和下界
最佳、最坏和平均情况
- 最佳情况 (Best Case):
- 定义:对于特定算法,最佳情况是指在输入数据中导致最短运行时间的情形。通常是算法能够以最快速度完成任务的情况。
- 例子:在顺序搜索中,如果要查找的元素恰好是第一个元素,则这是最佳情况。
- 最坏情况 (Worst Case):
- 定义:最坏情况是指在所有可能的输入数据中,导致算法最长运行时间的情形。这种情况下,算法的效率最低,通常用于评估算法的极限性能。
- 例子:在顺序搜索中,如果要查找的元素是最后一个元素或不存在于数组中,则这是最坏情况。
- 平均情况 (Average Case):
- 定义:平均情况是考虑所有可能输入的情况下,算法的预期运行时间。这通常需要对输入数据的分布有一定的了解。
- 例子:在顺序搜索中,平均情况下需要检查大约一半的元素。
上界和下界
- 上界 (Upper Bound):
- 定义:上界表示算法的运行时间在最坏情况下不会超过的界限。它为算法的运行时间提供了一个最坏情况的性能界限,通常使用大 O 符号表示。
- 例子:对于某个排序算法,运行时间的上界可以是 \(O(n^2)\),这意味着在最坏情况下,算法的时间复杂度不会超过这个界限。
- 下界 (Lower Bound):
- 定义:下界表示算法的运行时间在最佳情况下不会低于的界限。它为算法的运行时间提供了一个最佳情况的性能界限,通常使用大 Ω 符号表示。
- 例子:对于某个排序算法,运行时间的下界可以是 \(Ω(n \log n)\),这意味着在最佳情况下,算法的时间复杂度不会低于这个界限。
关系与应用
- U/L Bounds 与 B/W/A Cases:
- 上界和下界主要关注算法的增长速率,而最佳、最坏和平均情况则专注于特定输入类型导致的运行时间。
- 上界和下界可以用于描述算法在最佳、最坏和平均情况下的运行时间。例如,一个算法的运行时间可能在最坏情况下为 \(O(n^2)\),在最佳情况下为 \(Ω(n)\)。
算法分析:平均情况与时间复杂度
时间复杂度 $ T(n) = c_1 n^2 + c_2 n $
- 给定条件:
- $ c_1, c_2 > 0 $
- 该算法的时间复杂度在平均情况下为 $ T(n) = c_1 n^2 + c_2 n $。
- 大 O 符号分析:
- 上界:
- 对于所有 $ n > 1 \(:\) T(n) = c_1 n^2 + c_2 n (c_1 + c_2) n^2 $ 其中 $ c = c_1 + c_2 $。
- 因此,可以得出: $ T(n) cn^2 n_0 = 1 $
- 下界:
- 对于所有 $ n > 1 \(:\) T(n) = c_1 n^2 + c_2 n c_1 n^2 $
- 因此,可以得出: $ T(n) c_1 n^2 n_0 = 1 $
- 上界:
常数时间操作
- 读取数组首位置的值:
- 从数组的第一位置读取值的操作时间是常数时间。
- 不论数组大小如何,读取数组的第一个元素都只需固定的时间 $ T(n) = c $。
- 时间复杂度的分类:
- 对于这种常数时间的操作,我们通常将其归类为:
- 最佳情况: $ T(n) = c $
- 最坏情况: $ T(n) = c $
- 平均情况: $ T(n) = c $
- 对于这种常数时间的操作,我们通常将其归类为:
- 总结:
- 由于该操作的时间复杂度是常数时间,因此可以表示为: $ T(n) O(1) $
分析算法 vs. 分析问题
1. 分析算法
- 目的:
- 评估一个具体算法的效率和性能,通常通过计算其时间复杂度和空间复杂度来完成。
- 内容:
- 上界和下界:
- 在分析特定算法时,确定其最坏情况下的时间复杂度(上界)和最佳情况下的时间复杂度(下界)。
- 实际运行时:
- 实际测量算法在不同输入规模下的表现,以观察其性能。
- 上界和下界:
- 结果:
- 提供关于特定算法在解决特定问题时的效率的洞见。
2. 分析问题
- 目的:
- 研究一个问题本身的复杂性,不依赖于已知的算法。
- 内容:
- 问题的上界:
- 理论上,问题的上界是一个不依赖于任何已知算法的复杂性度量。也就是说,即使我们没有找到最优算法,问题的复杂性仍然存在。
- Ω(f(n))表示:
- 如果一个问题属于 \(\Omega(f(n))\),则解决这个问题的每个算法都必须至少具有 \(f(n)\) 的计算量。这意味着,任何算法都无法在低于这个计算量的情况下解决该问题。
- 问题的上界:
- 结果:
- 通过研究问题本身的复杂性,可以发现算法设计的限制和潜在的改进空间。
3. 理论分析
- 上界的关系:
- 问题的上界不能低于当前已知的最佳算法的上界。
- 如果一个问题有一个已知的最佳算法,其时间复杂度为 \(g(n)\),那么问题的上界 \(h(n)\) 必须满足: $ h(n) g(n) $
- 也就是说,尽管随着新算法的发现,问题的上界可能会提高,但在任何给定的时间点上,问题的上界至少等于当前最佳算法的上界。
- Ω表示的含义:
- 如果一个问题属于 \(\Omega(f(n))\),这表明解决该问题至少需要 \(f(n)\) 的计算量。这对于理解算法的限制非常重要,因为这意味着即使是尚未设计的算法也必须遵循这个复杂性界限。





