
Chapter 2 Instruction Set Architecture
Chapter 2 Instruction Set Architecture
这一章会比较容易接受,先解决比较容易接受的,最后回头去看第八章,第八章比起第九章还会简单一些,最难的已经解决了,其他的不过是时间问题罢了,不要打一百次战斗都胜利,要一次战斗保证以后不用再战斗了。
## Contents
| 英文内容 | 中文翻译 |
|---|---|
| 2.1 Instruction and Instruction Sequencing | 2.1 指令与指令序列 |
| 2.2 Instruction Formats | 2.2 指令格式 |
| 2.3 Addressing Modes | 2.3 寻址方式 |
| 2.4 Stacks | 2.4 栈 |
| 2.5 Subroutines | 2.5 子程序 |
| 2.6 CISC Instruction Sets | 2.6 CISC 指令集 |
| 2.7 RISC and CISC Styles | 2.7 RISC 和 CISC 风格 |
2.1 Instruction and Instruction Sequencing
| 英文内容 | 中文翻译 |
|---|---|
| Register Transfer Notation | 寄存器传送符号 |
| Assembly Language Notation | 汇编语言符号 |
| RISC and CISC Instruction Sets | RISC 和 CISC 指令集 |
| Introduction to RISC Instruction Sets | RISC 指令集简介 |
| Instruction Execution and Straight Line Sequencing | 指令执行与直线顺序 |
| Branching | 分支 |
指令与指令序列
四种类型的指令:
- 内存与处理器寄存器之间的数据传送。
- 对数据进行的算术和逻辑操作。
- 程序顺序和控制。
- 输入/输出传输。
寄存器传送符号(Register Transfer Notation)
- 寄存器传送符号用于描述硬件级别的数据传送和操作。
- 处理器寄存器:如 R0、R5。
- I/O 寄存器:如 DATAIN、OUTSTATUS。
- 内存位置:如 LOC、PLACE、A、VAR2。
- 符号表示:
- 用
[...]表示某个位置的内容。 - 用
<-表示数据传送到目标位置。
- 用
寄存器传送符号示例
- 示例 1:
R2 <- [LOC]- 解释:将内存中的 LOC 的内容传送到寄存器 R2。
- 右边的表达式始终表示一个值,左边的表达式始终表示一个位置。
- 示例 2:
R4 <- [R2] + [R3]- 解释:将寄存器 R2 和 R3 的内容相加,并将结果存储在寄存器 R4 中。
汇编语言符号(Assembly Language Notation)
1. 概述
- RTN(寄存器传送符号):显示数据传输和算术运算。
- 但是 RTN 不适合表示完整的机器指令和程序。
- 为此目的,需要一种专用的符号表示法——汇编语言。
2. 汇编语言示例
- 对于之前用 RTN 表示的两个示例:
- RTN 表示:
R2 <- [LOC]
R4 <- [R2] + [R3]
- 汇编语言表示:
Load R2, LOC(加载内存 LOC 的内容到寄存器 R2)Add R4, R2, R3(将寄存器 R2 和 R3 的值相加,结果存储在寄存器 R4)
- RTN 表示:
3. 汇编指令的基本组成
- 一条指令包括:
- 指定的操作(Desired Operation)。
- 涉及的操作数(Operands)。
4. 操作符表示法
- 本章使用示例:
- 英文单词表示操作符,如
Load、Store、Add等。
- 英文单词表示操作符,如
- 商用处理器的表示:
- 使用助记符(Mnemonics),通常是操作的缩写,例如:
LD表示 Load。ST表示 Store。ADD表示 Add。
- 注意:不同处理器的助记符可能有所不同。
- 使用助记符(Mnemonics),通常是操作的缩写,例如:
RISC 和 CISC 指令集
1. 指令集的本质
- 指令的性质是区分计算机架构的关键因素。
- 现代计算机的两种基本指令集设计方法:
- 精简指令集计算机(RISC, Reduced Instruction Set Computers)。
- 复杂指令集计算机(CISC, Complex Instruction Set Computers)。
2. RISC 指令集(精简指令集计算机)
- 特点:
- 指令简短:每条指令通常为一个字(one word)。
- 操作数要求:算术操作数必须在寄存器中,不能直接从内存中获取。
- 指令集较小:通常只有 32 条左右 的指令。
- 指令简单:每条指令通常在 一个时钟周期 内完成。
- 高效的流水线:由于指令的固定长度和简单性,能更有效地使用流水线技术。
- 示例:
- ARM 架构是一种典型的 RISC 架构。
3. CISC 指令集(复杂指令集计算机)
- 特点:
- 指令复杂:支持多字指令(multi-word instructions)。
- 操作数灵活:允许操作数直接从内存中获取或存储。
- 指令数量多:通常包含 几百条指令。
- 执行周期长:一条指令可能需要 多个时钟周期 才能完成。
- 示例:
- X86 架构是一种典型的 CISC 架构。
表格总结
这里的长度和操作数的获取需要注意一下,其他随便看一下就好了。
| 特性 | RISC | CISC |
|---|---|---|
| 指令长度 | 固定长度(通常 1 个字) | 可变长度(多字指令) |
| 操作数获取 | 必须从寄存器中获取 | 可直接从内存中获取或存储 |
| 指令数量 | 少量(约 32 条) | 大量(几百条指令) |
| 指令复杂度 | 简单,每条指令一个时钟周期完成 | 复杂,可能需要多个时钟周期完成 |
| 流水线效率 | 高效,易于实现流水线 | 流水线实现难度较高 |
| 示例 | ARM 架构 | X86 架构 |
RISC 强调简单和高效,适合现代处理器的流水线设计;而 CISC 提供灵活性,适合复杂操作和早期的编程需求。
RISC 指令集(RISC Instruction Sets)
1. RISC 指令集的两个关键特性
- 固定长度指令:每条指令占用一个字(single
word)。
- 加载/存储架构(Load/Store Architecture):
- 访问内存操作数:只能通过 Load 和
Store 指令进行。
- 算术/逻辑运算的操作数:必须在寄存器中,或者有一个操作数可以在指令字中显式提供。
- 访问内存操作数:只能通过 Load 和
Store 指令进行。
2. 初始状态与数据传输
初始存储:所有指令和数据最初都存储在内存中。
寄存器操作数需求:由于 RISC 指令需要寄存器操作数,因此在算术运算前必须完成数据传输。
加载指令(Load):用于从内存将数据传输到寄存器,格式为:
1
Load processor_register, mem_location
寻址方式:指定内存位置的寻址模式将在后续部分讨论。
3. 高级语言语句示例:C = A + B
A、B、C 对应于内存位置。
RTN 表达式:
1
C <- [A] + [B]
执行步骤:
- 获取内存位置 A 和 B 的内容。
- 计算和。
- 将结果存储到内存位置 C。
- 获取内存位置 A 和 B 的内容。
4. 实现任务的简单 RISC 指令序列
Load R2, A:将内存位置 A 的内容加载到寄存器 R2 中。
Load R3, B:将内存位置 B 的内容加载到寄存器 R3 中。
Add R4, R2, R3:将寄存器 R2 和 R3 的内容相加,结果存储在寄存器 R4 中。
Store R4, C:将寄存器 R4 的内容存储到内存位置 C 中。
5. 指令说明
- Load 指令:将数据从内存加载到寄存器中。
- Store 指令:将数据从寄存器存储到内存中。
- 注意:
- Load 指令的源是内存,目标是寄存器。
- Store 指令的源是寄存器,目标是内存。
- 源和目标的顺序在两种指令中是相反的。
- Load 指令的源是内存,目标是寄存器。
分支(Branching)
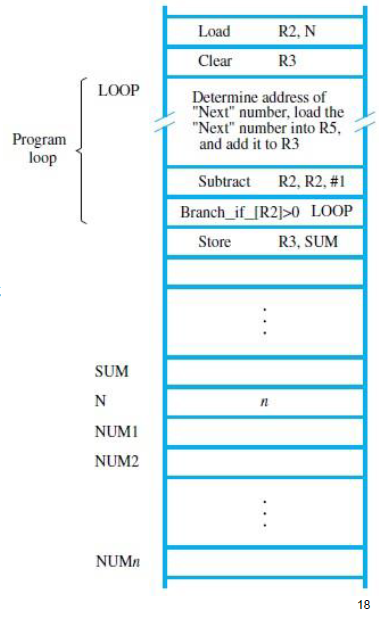
1. 示例任务:累加 n 个数
- 将一组包含 n 个数字的列表进行求和。
- 实现方法:
- 使用单独的 Load 指令加载每个数。
- 使用 Add 指令将数字依次累加到寄存器中。
2. 程序循环(Program Loop)
- 对于累加 n 个数的操作,可以通过 循环(Loop)
来实现:
- 每次迭代加载一个数。
- 累加后更新结果。
- 条件满足时退出循环。
3. 分支指令(Branch Instructions)
- 功能:分支指令通过加载新地址到程序计数器(PC)来实现跳转。
- 分支目标(Branch Target):
- 分支跳转后程序执行的新地址。
- 条件分支(Conditional Branch):
- 分支跳转的执行依赖于某些条件是否满足。
4. 条件分支示例
功能描述:比较两个寄存器的内容并基于条件跳转。
RTN 表示:
1
Branch_if [R4] > [R5] Loop
- 如果寄存器 R4 的内容大于 R5,则跳转到
Loop位置。 - 否则,继续顺序执行。
- 如果寄存器 R4 的内容大于 R5,则跳转到
5. 条件码(Condition Codes)
- 用途:条件码用于标识最近一次指令执行的结果(如比较运算的结果)。
- 典型条件:
- 零标志(Zero Flag, ZF):结果是否为零。
- 负标志(Negative Flag, NF):结果是否为负数。
- 溢出标志(Overflow Flag, OF):是否发生溢出。
- 进位标志(Carry Flag, CF):是否发生进位或借位。
2.2 指令格式(Instruction Formats)
1. 什么是机器指令(Machine Instruction)?
- 定义:
机器指令是通过处理器电路执行特定任务的行为描述。
- 特点:
- 指令直接指定了处理器必须完成的操作。
- 通常以汇编语言代码表示。
- 指令直接指定了处理器必须完成的操作。
2. 什么是指令集(Instruction Set)?
- 定义:
指令集是处理器可以执行的所有不同机器指令的集合。
- 作用:
- 定义了处理器的功能范围和执行能力。
- 不同的处理器拥有不同的指令集,例如 RISC 指令集和 CISC 指令集。
- 定义了处理器的功能范围和执行能力。
机器指令的组成要素(Elements of a Machine Instruction)
1. 操作码(Opcode)
- 定义:
操作码用于指定指令要执行的操作,例如加法(ADD)、输入/输出(I/O)等。
- 表示方式:
操作码通常以二进制代码表示。
2. 源操作数引用(Source Operand Reference)
- 作用:
指定指令所需的操作数来源。
- 操作数的位置:
- 主存储器或虚拟存储器:从内存中加载操作数。
- 处理器寄存器:直接从寄存器中获取操作数。
- I/O 设备:操作数来自输入/输出设备。
- 主存储器或虚拟存储器:从内存中加载操作数。
3. 结果操作数引用(Result Operand Reference)
- 作用:
指定操作结果存储的位置。
- 可能的位置:
- 主存储器或虚拟存储器。
- 处理器寄存器。
- I/O 设备。
4. 下一条指令引用(Next Instruction Reference)
- 作用:
指定下一条要执行的指令的位置。
- 特点:
- 隐式引用:在大多数情况下,下一条指令不需要在当前指令中显式指定。
- 顺序执行:通常情况下,下一条指令是程序中逻辑上紧随当前指令的一条(按线性或顺序方式执行)。
- 隐式引用:在大多数情况下,下一条指令不需要在当前指令中显式指定。
指令表示(Instruction Representation)
1. 指令的表示方式
- 在计算机中:
每条指令由一系列二进制位(binary bits)表示。
- 指令的划分:
指令通常分为两个字段:- 操作码字段(Operation Code Field, Opcode):
- 指定要执行的操作,例如加法、存储等。
- 地址字段(Address Field):
- 指定操作数或结果的位置。
- 操作码字段(Operation Code Field, Opcode):
指令设计准则(Instruction Design Criteria)
1. 指令长度
- 短指令优于长指令:
- 短指令能够节省存储空间并提高处理速度。
- 然而,指令长度必须足够表达操作码和地址信息。
- 短指令能够节省存储空间并提高处理速度。
2. 操作表达能力
- 指令格式需要提供足够的空间来表示所有期望执行的操作。
3. 地址字段的位数
- 地址字段的位数直接影响:
- 可访问的内存范围(地址范围)。
- 对处理器架构的复杂性要求。
- 可访问的内存范围(地址范围)。
示例:指令格式
1 | Opcode Address |
- Opcode(操作码):指令的功能部分,例如 ADD、LOAD
等。
- Address(地址):存储操作数或结果的位置的指针。
指令地址字段格式(Instruction Address Field Formats)
1. 零地址指令(Zero-address Instruction)
特点:
- 指令中不需要显式地址字段。
- 通常用于 栈结构,操作数隐式存储在栈顶。
- 指令中不需要显式地址字段。
操作形式:
1
Opcode
- 例如,栈中顶层两个操作数进行操作,结果放回栈顶。
2. 单地址指令(One-address Instruction)
特点:
- 指令中包含一个显式地址字段。
- 通常假设另一个操作数存储在处理器的累加器(Accumulator, AC)中。
- 指令中包含一个显式地址字段。
操作形式:
1
OP [A] → A
- [A]:操作数存储位置。
- A:运算结果存储的位置。
- 累加器:隐式作为另一个操作数和存储结果的位置。
- [A]:操作数存储位置。
格式:
1
Opcode A
3. 双地址指令(Two-address Instruction)
特点:
- 指令中包含两个显式地址字段。
- 一个地址用于来源操作数,另一个地址用于目标操作数。
- 指令中包含两个显式地址字段。
操作形式:
1
[A1] OP [A2] → A1
- A1:目标操作数的地址,也是结果的存储位置。
- A2:来源操作数的地址。
- A1:目标操作数的地址,也是结果的存储位置。
格式:
1
Opcode A1 A2
4. 三地址指令(Three-address Instruction)
特点:
- 指令中包含三个显式地址字段。
- 可直接指定两个来源操作数和一个结果存储位置。
- 指令中包含三个显式地址字段。
操作形式:
1
[A2] OP [A3] → A1
- A1:结果存储位置。
- A2、A3:来源操作数的地址。
- A1:结果存储位置。
格式:
1
Opcode A1 A2 A3
精华
指令地址字段的设计直接影响处理器的复杂性和性能:
- 零地址指令 简单,常用于栈操作。
- 单地址指令 通过累加器简化设计。
- 双地址指令 和 三地址指令 提供更灵活的操作,适合复杂运算,但指令长度更长。
指令长度(Instruction Length)
1. 指令长度的类型
- 固定长度指令(Fixed Length):
- 所有指令长度相同。
- 优点:简化指令解码,提高处理器的执行效率。
- 缺点:可能会浪费存储空间,尤其是简单指令的编码。
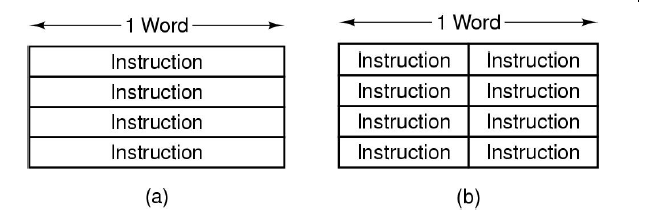
- 可变长度指令(Variable Length):
- 不同指令的长度可以不同。
- 优点:灵活性更高,复杂指令可以使用更多位,简单指令可以使用较短编码。
- 缺点:增加了解码的复杂性,可能降低执行速度。
- 不同指令的长度可以不同。
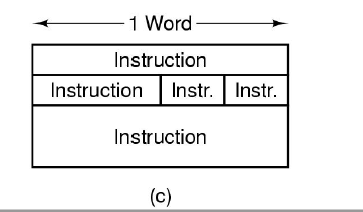
2. 缩短指令长度的方法
- 重复使用操作数(Operand Reuse):
- 说明:
如果一个操作数需要被多次使用,可以将其先加载到寄存器中。
- 注意:
- 仅当操作数多次使用时,这种方式才有意义。
- 如果操作数只使用一次,将其放入寄存器反而会增加额外开销。
- 仅当操作数多次使用时,这种方式才有意义。
- 说明:
- 隐式指定操作数(Implicit Operand Specification):
- 说明:
隐式地指定某些常用操作数或操作方式,而不是显式地在指令中提供地址。
- 示例:
- 累加器(Accumulator, AC)作为默认的目标或来源操作数。
- 栈操作中,栈顶元素作为隐式操作数。
- 累加器(Accumulator, AC)作为默认的目标或来源操作数。
- 说明:
精华
指令长度的设计需要在执行效率和存储空间之间找到平衡:
- 固定长度指令 更适合简化解码和流水线处理。
- 可变长度指令 在存储和复杂指令表示方面更灵活。
通过重复使用操作数和隐式指定操作数,可以有效缩短指令长度,同时减少存储和传输成本。
操作码格式(Opcode Format)
1. 固定长度操作码(Fixed Length Opcode)
- 特点:
- 操作码长度固定,但指令的总长度是可变的。
- 设定操作码为 k 位,操作数地址为 n
位。
- 这种格式允许:
- \(2^k\)
种不同的操作(可支持不同的操作指令)。
- \(2^n\) 个可寻址的内存单元(指定操作数的地址)。
- \(2^k\)
种不同的操作(可支持不同的操作指令)。
2. 可变长度操作码(Variable Length Opcode)
特点:
- 操作码的长度是可变的,通常指令的长度是固定的,操作码和操作数地址的长度相互制约。
- 举例:
- 如果指令长度为 16 位,操作数地址为 4
位,设计者的需求如下:
- 需要支持 15 条三地址指令
- 需要支持 14 条二地址指令
- 需要支持 31 条一地址指令
- 需要支持 16 条零地址指令
- 需要支持 15 条三地址指令
- 如果指令长度为 16 位,操作数地址为 4
位,设计者的需求如下:

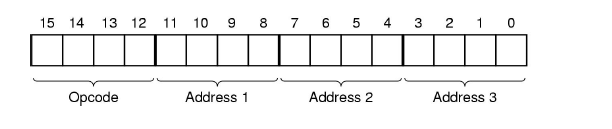
3. 设计示例:
- 16 位指令长度,4 位操作数地址:
- 设计可能为 4 位操作码,每条指令有
三个地址,可以设计 15 条三地址指令。
- 4 位操作码可以表示 16 种操作,可以涵盖大部分基本操作。
- 如果需要更多的操作指令,则可以扩展操作码的长度。例如,将操作码扩展到 8 位,然后可以设计 14 条二地址指令,并支持更多种类的操作。
- 设计可能为 4 位操作码,每条指令有
三个地址,可以设计 15 条三地址指令。
- 具体设计:
- 三地址指令:
- 4 位操作码,允许 15
条三地址指令,即操作码范围为
0000到1110(15 种操作)。
- 4 位操作码,允许 15
条三地址指令,即操作码范围为
- 二地址指令:
- 8 位操作码,允许 14
条二地址指令,即操作码范围为
1111 0000到1111 1101(15 到 32 的操作)。
- 8 位操作码,允许 14
条二地址指令,即操作码范围为
- 一地址指令:
- 12 位操作码,允许 31
条一地址指令,即操作码范围为
1111 1111 0 0000到1111 1111 1110。
- 12 位操作码,允许 31
条一地址指令,即操作码范围为
- 零地址指令:
- 16 位操作码,可以设计 16
条零地址指令,即操作码范围为
1111 1111 1111 0000到1111 1111 1111 1111。
- 16 位操作码,可以设计 16
条零地址指令,即操作码范围为
- 三地址指令:
2.3 寻址方式 (Addressing Modes)
寻址方式是指在指令中指定操作数位置的不同方法,决定了如何解释指令中的地址字段。
1. 什么是寻址方式?
- 寻址方式指的是在指令中,操作数的位置是如何被指定的。换句话说,就是在机器指令中,地址字段是如何被解释的。通过寻址方式,计算机能够知道在哪里查找操作数(例如,寄存器、内存、I/O 设备等)。
2. 为什么需要寻址方式?
- 计算机指令可能包含直接的数据(例如立即数),也可能包含指向数据的地址。不同的寻址方式使得指令能够灵活地访问数据,提升程序的效率和表达能力。通过采用不同的寻址方式,可以在内存、寄存器、甚至外部设备之间高效地进行操作。
3. 常见的寻址方式种类:
立即寻址(Immediate Addressing)
操作数直接在指令中给出,不需要进一步访问内存或寄存器。例如,在指令中直接指定一个常数。寄存器寻址(Register Addressing)
操作数位于处理器的寄存器中,指令通过指定寄存器编号来访问数据。直接寻址(Direct Addressing)
指令中的地址字段直接指向内存中的某个位置,操作数存储在该内存地址中。间接寻址(Indirect Addressing)
指令中的地址字段提供的是内存地址的地址(即间接地址),首先需要访问该内存地址,获取指向实际操作数的地址。变址寻址(Indexed Addressing)
基地址加上偏移量,用于计算操作数的实际位置。适用于数组等结构的存取。相对寻址(Relative Addressing)
基地址是程序计数器(PC)的值,通常用于实现跳转指令。
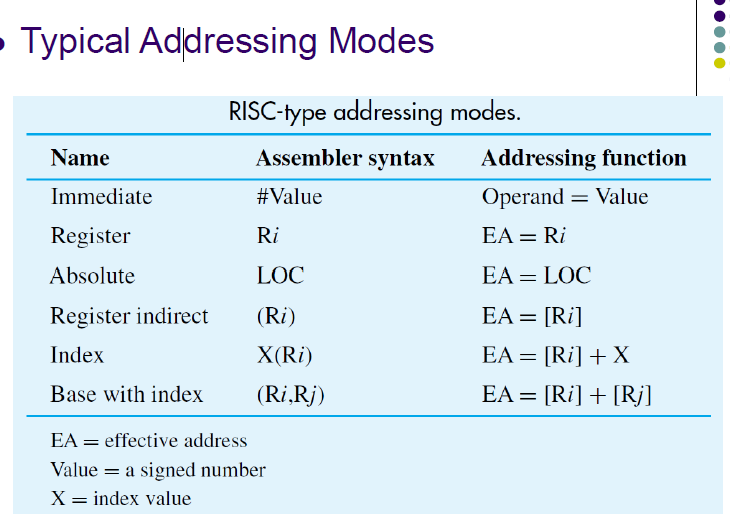
立即寻址(Immediate Mode)
1. 定义
- 立即寻址模式下,操作数直接在指令中给出,而不是存储在内存或寄存器中。
2. 示例
- 示例:
Add R4, R6, #200
该指令的含义是将常数200加到寄存器R6的内容中,结果存储到寄存器R4。
3. 使用场景
- 定义和使用常量:立即寻址常用于在程序中定义常数。
- 设置变量的初始值:可以直接在指令中设置变量的初始值。
4. 优点
- 不需要额外的内存引用:操作数直接包含在指令中,除了获取指令本身之外,不需要其他的内存访问。
5. 缺点
- 只能使用常数:立即寻址只能提供常数作为操作数,无法使用变量或内存中的值。
- 操作数大小有限制:由于操作数被嵌入指令中,操作数的大小受到指令中地址字段的限制。如果常数太大,可能无法容纳在指令内。
绝对寻址(Absolute Mode / Direct Mode)
1. 定义
- 绝对寻址模式下,操作数存储在内存中的某个位置,而该位置的地址会在指令中明确给出。
2. 示例
示例:
Load R2, NUM1
该指令表示将存储在内存位置NUM1中的值加载到寄存器R2。EA = A
- EA(有效地址):指向包含引用操作数的内存位置的实际地址。
- A:指令中的地址字段内容,指示内存位置的地址。
3. 使用场景
- 访问全局变量:当全局变量的地址在编译时已知,可以使用绝对寻址直接访问这些变量。
4. 优点
- 单次内存引用:操作数直接由指令中的地址字段指定,只需要一次内存引用,不需要额外的计算。
5. 缺点
- 固定内存地址:指令总是访问相同的内存位置,无法动态变化。
- 有限的地址空间:由于地址字段的大小限制,绝对寻址只能提供一个有限的地址空间。如果程序需要更多的地址,可能无法满足需求。
间接寻址模式(Indirect Mode)
间接寻址模式允许通过内存位置间接访问操作数,这种寻址方式通常出现在 CISC 风格的处理器中。具体来说,操作数的有效地址(EA)是存储在一个内存位置中的地址,而该内存位置的地址本身由指令提供。
EA = [A]
- EA(有效地址):表示操作数的实际内存地址,它是通过指令提供的内存位置
A中存储的内容获取的。 - A:指令中的地址字段,指向存储有效地址的内存位置。
EA = [A]表示指令中的地址字段 A 指向一个内存位置,该位置存储的是操作数的有效地址。
示例:
假设有指令 Add (A), R0,意味着:
A指向一个内存位置,该内存位置存储着另一个内存地址,这个地址就是实际的操作数所在位置。- 执行时,指令首先访问内存位置
A,获取该位置中存储的地址(假设为B),然后从地址B处获取操作数,将其加到寄存器R0中。
优缺点:
优点:
- 广泛的地址空间:如果内存字长为
N位,则地址空间可达到 2^N,使得可以访问更大范围的内存。
缺点:
- 两次内存引用:指令执行需要两次内存引用:
- 第一次访问获取有效地址
EA(即获取指令中的地址A所存储的内容)。 - 第二次访问使用获取的地址
EA获取操作数的实际值。
- 第一次访问获取有效地址
多级间接寻址(Multilevel Indirect Addressing)
- EA = […[A]…]:表示多级间接寻址,首先从内存位置
A获取地址,再通过该地址获取下一级地址,依此类推。 - 在这种模式中,指令可能包含一个“间接标志”(I
bit),用于指示是否需要进行多级间接寻址:
- I bit = 0:表示指令中的地址字段 A 直接包含有效地址。
- I bit = 1:表示需要进一步间接寻址,即通过
A获取另一个地址,直到找到实际的操作数。
精华:
- 间接寻址模式 提供了较大的地址空间,但由于需要多次内存访问来获取操作数,因此会增加指令执行的时间。
寄存器寻址模式(Register Mode)
寄存器寻址模式是指操作数存储在处理器的寄存器中,而指令中包含寄存器的地址。
EA = Ri
- EA(有效地址):等于寄存器
Ri的内容。 - Ri:指令中地址字段的内容,指向一个寄存器,指示该寄存器存储了操作数。
示例:
假设有指令 Add R4, R2, R3,表示:
- 这条指令将寄存器
R2和寄存器R3的内容相加,并将结果存储到寄存器R4中。 - 这里,寄存器
R2和R3的内容作为操作数,R4是结果寄存器。
优缺点:
优点:
- 小地址字段:指令中的地址字段非常小,只需要指定寄存器号,不需要复杂的内存地址。
- 无需内存访问:操作数直接存在寄存器中,执行指令时无需访问内存,因此执行速度更快。
缺点:
- 有限的地址空间:由于操作数只能存储在寄存器中,寄存器数量有限,因此这种方式的可寻址范围很小,只能访问处理器内部的寄存器。
寄存器间接寻址模式(Register Indirect Mode)
在寄存器间接寻址模式中,操作数的有效地址是由寄存器中的内容指定的,而寄存器的地址是在指令中给出的。
EA = [Ri]
- EA(有效地址):表示由寄存器
Ri中的内容提供的内存地址,指向存储操作数的内存位置。 - Ri:指令中的地址字段,指向一个寄存器,寄存器的内容指示实际存储操作数的内存地址。
示例:
假设有指令 Load R2, (R5),表示:
- 这条指令首先从寄存器
R5中获取一个地址(即R5的内容),然后使用这个地址从内存中加载数据到寄存器R2中。 - 这里,寄存器
R5存储了目标操作数的内存地址,指令将数据从该内存地址加载到R2。
优缺点:
优点:
- 灵活性更强:可以通过寄存器间接寻址来访问大量的内存地址,增加了寻址的灵活性和可扩展性。
- 节省空间:可以通过寄存器来存储内存地址,避免在指令中直接使用较长的内存地址。
缺点:
- 需要额外的内存访问:需要访问寄存器以获取有效地址,然后访问内存。这意味着执行指令时需要两个内存访问操作,可能会影响执行速度。
示例:
使用寄存器间接寻址模式访问 n
个数字列表。假设寄存器中存储了列表的起始地址,通过该寄存器可以间接访问列表中的元素。具体来说,指令会先从寄存器中读取一个地址,然后使用该地址来访问内存中的数据。

图 2.8: 使用间接寻址访问列表中的元素
在程序设计中,可以通过寄存器间接寻址来高效地操作数组或列表。例如,寄存器中存储了数组的起始地址,而指令通过间接寻址方式访问数组中的不同元素,减少了对内存地址的直接操作。
优点:
- 减少指令中的内存地址引用: 通过寄存器间接寻址,可以避免在每条指令中都直接写入完整的内存地址。指令中只需包含寄存器的地址,而寄存器的内容则指向所需的内存位置。
- 减少内存访问次数: 寄存器间接寻址模式通过寄存器存储内存地址,减少了直接从内存中提取长地址的开销,从而提高了程序的执行效率,尤其在多次访问连续内存地址时,能显著降低内存访问的延迟。
总结:
寄存器间接寻址模式通过在寄存器中存储内存地址来访问内存,减少了对内存地址的显式引用,并能减少内存访问次数,提高了程序的效率。
索引寻址模式(Indexed Mode)
基本概念:
在索引寻址模式中,操作数的有效地址是通过将寄存器(索引寄存器)中的值与指令中给定的常数值(偏移量)相加生成的。
- 有效地址(EA) = X +
[Ri]
其中:- X 是指令中的常数值(偏移量),
- [Ri] 是寄存器中的值,即索引寄存器的内容。
需要注意的是,在生成有效地址的过程中,索引寄存器的内容不会改变。
示例:
- X(Ri):指令中包含常数偏移量 X 和一个寄存器 Ri,操作数的有效地址是通过将 X 和 Ri 的内容相加得到的。
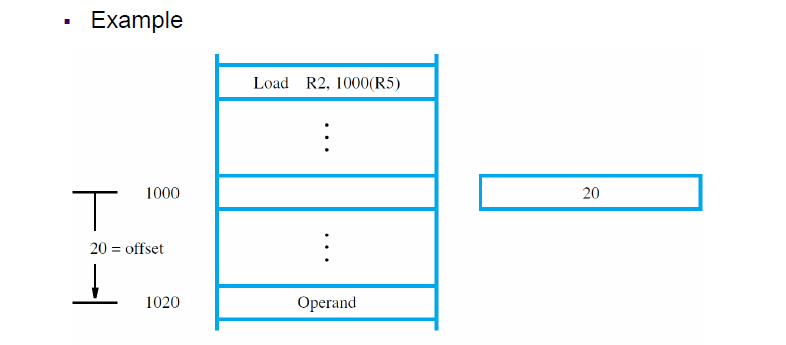
索引寻址模式的两种使用方式:
偏移量作为常数给出:
在这种方式下,偏移量 X 是指令中直接给出的常数。例如:
Load R2, 100(R1),表示将寄存器 R1 中的值加上 100,得到操作数的有效地址,然后从该地址加载数据到寄存器 R2。偏移量存储在索引寄存器中:
这种方式要求指令中有一个足够大的偏移量字段来存储地址。此时,索引寄存器的内容加上该偏移量字段值,形成操作数的有效地址。
使用场景:
索引寻址模式常用于访问数据结构中相对于某个基准位置的操作数。比如,访问数组中的元素时,数组元素的存储地址是相对于数组基地址的一个偏移量。
示例:
- N 行 4 列的数组,如果内存是字节可寻址且字长为 32 位,那么可以通过索引寻址方式高效地访问数组中的各个元素。
索引寻址模式的变种:
- 基址加索引(Base with Index):
- (Ri, Rj):使用两个寄存器,一个寄存器 Ri 作为索引寄存器,另一个寄存器 Rj 作为基址寄存器。
- 有效地址(EA) = [Ri] + [Rj]
- 基址加索引加偏移量(Base with Index and Offset):
- X(Ri, Rj):使用一个偏移量 X
和两个寄存器 Ri 和 Rj。
- 有效地址(EA) = [Ri] + [Rj] + X
- X(Ri, Rj):使用一个偏移量 X
和两个寄存器 Ri 和 Rj。
这种寻址方式可以非常灵活地访问多维数据结构(如矩阵、表格等)。
精华:
索引寻址模式通过将寄存器内容与指令中的偏移量相加,生成操作数的有效地址。它非常适合用于处理复杂的数据结构(如数组和表格),提高了对数据的访问效率。
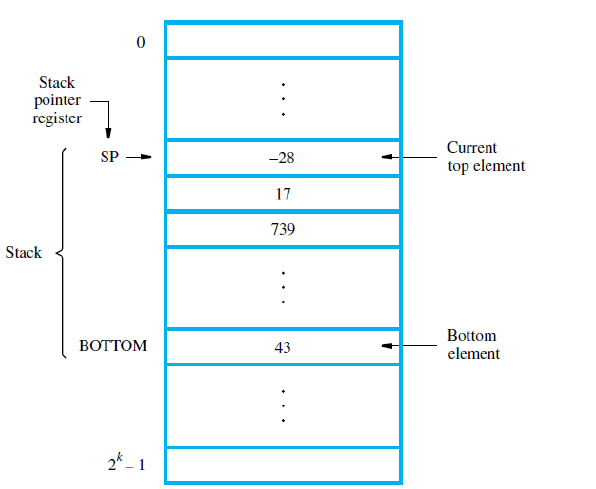
栈(Stacks)
栈是一种数据元素的列表,通常是按字(word)存储的,具有以下访问限制:元素只能在列表的一端添加或移除。栈通常被称为“后进先出栈(LIFO)”或“压入栈(Pushdown Stack)”。
操作:
- Push(压栈): 将一个新元素放入栈顶。
- Pop(弹栈): 从栈顶移除一个元素。
栈的实现:
- 在现代计算机中,栈通常通过主存的一部分来实现。
- 程序员可以在内存中创建一个栈。
- 计算机系统中通常还有一个专用的处理器栈。
处理器栈(Processor Stack)
- 处理器有一个栈指针(SP)寄存器,指向栈顶。
- 假设内存是字节可寻址,字长为 32 位。
Push 操作:
- Push 操作通常需要两个指令:
- Subtract SP, SP, #4:将栈指针 SP 减少 4,准备为新的数据元素腾出空间。
- Store Rj, (SP):将寄存器 Rj 的内容存储到栈顶(即栈指针所指的位置)。
Pop 操作:
- Pop 操作也通常需要两个指令:
- Load Rj, (SP):从栈顶(栈指针所指的位置)加载数据到寄存器 Rj。
- Add SP, SP, #4:将栈指针 SP 增加 4,移除栈顶元素的空间。
子程序(Subroutines)
在程序中,一个特定的任务可能会多次执行,并且使用不同的数据。例如:数学函数、列表排序等。为了避免在程序中多次重复相同的代码,我们可以将该任务实现为一个子程序。通过调用子程序来执行任务,而不是在程序的每个部分都复制整个子程序代码。
子程序调用:
- 子程序调用使用的是特殊类型的分支指令,称为Call 指令。
子程序连接(Subroutine Linkage)
子程序可以从不同的地方被调用。如何确保子程序返回到正确的位置,这是子程序连接的问题。
- Call 指令执行时,会将程序计数器(PC)更新为指向 Call 指令之后的那一条指令。
- 保存返回地址:这个地址需要被保存,以便 Return 指令使用。
- 最简单的方法是将返回地址存储在链接寄存器(Link Register)中。
- Call 指令的执行过程:
- 将更新后的 PC 内容存储到链接寄存器。
- 分支跳转到子程序的目标位置。
返回(Return)
- 返回时,Return 指令通过跳转到链接寄存器中保存的地址来完成。
子程序嵌套(Subroutine Nesting)与处理器栈(Processor Stack)
允许一个子程序调用另一个子程序,这就形成了子程序嵌套。子程序的链接寄存器内容在第二次子程序调用时会被覆盖。
- 解决办法: 第一个子程序在第二个子程序调用之前,应该将链接寄存器的内容保存到处理器栈中。
- 恢复链接寄存器: 在第二个子程序返回后,第一个子程序可以从栈中恢复链接寄存器的内容。
子程序嵌套的深度
子程序嵌套可以达到任意深度,返回地址会按照“后进先出(LIFO)”的顺序进行生成和使用。这意味着与子程序调用相关的返回地址应该被推送到处理器栈上。
总结:
- 子程序是程序中为执行某个特定任务而编写的一组指令,避免了重复代码。
- 子程序调用通过 Call 指令实现,返回通过链接寄存器和 Return 指令完成。
- 在子程序嵌套的情况下,返回地址被保存到处理器栈中,以支持多层嵌套的子程序调用。
CISC 指令集(CISC Instruction Sets)
CISC(复杂指令集计算机)指令集与加载/存储架构(load/store architecture)不同,后者要求算术和逻辑操作只能在处理器寄存器中的操作数上执行。
CISC 指令集特点:
不局限于加载/存储架构:
CISC 指令集可以直接在内存操作数上执行操作,而不需要首先将其加载到寄存器中。指令长度:
CISC 指令不一定都适应于单一的字长(单个机器字)。某些指令可能只占一个字,但也有可能跨越多个字节。大多数算术和逻辑指令使用两地址格式:
- 格式:操作数 目标, 源。
- 示例:
Add B, A
这会执行操作B ← [A] + [B],即对内存操作数执行加法。
移动指令(Move):
移动指令具有加载和存储指令的功能。- 格式:Move 目标, 源。
- 示例:
Move C, A,将 A 的内容移到 C 中。
- 格式:Move 目标, 源。
在某些 CISC 处理器中,其中一个操作数可以是内存中的内容,另一个操作数必须是寄存器。
- 示例:
Move Ri, A:将内存 A 中的内容移动到寄存器 Ri。
Add Ri, B:将寄存器 Ri 和内存 B 中的内容相加。
- 示例:
指令示例:
Move C, Ri:将寄存器 Ri 的内容移动到 C 中。Add C, A:将内存 A 中的内容加到 C 中。
总结:
- CISC 指令集支持更加复杂的操作,允许在内存和寄存器之间直接操作,指令长度灵活,且通常支持两地址操作模式。
- CISC 处理器可以通过多种方式直接对内存操作数进行算术或逻辑运算,而不必先将其加载到寄存器中。
自动增量和自动减量模式(Autoincrement and Autodecrement Mode)
自动增量模式(Autoincrement Mode)
- 定义:操作数的有效地址是指令中指定的寄存器内容。访问操作数后,该寄存器的内容会自动增加,指向列表中的下一个项目。
- 公式:
EA = [Ri],Ri 自动递增 - 用途:
这种模式非常适用于循环体内调整指针。例如:Add SUM, (Ri+):先取出 Ri 指向的值进行加法操作,然后 Ri 增加,指向下一个操作数。MoveByte (Rj+), Rk:将 Ri 指向的字节内容移到 Rk 中,同时 Ri 自动递增。- 增量量:对于字(words),递增为 4;对于字节(bytes),递增为 1。
自动减量模式(Autodecrement Mode)
- 定义:指令中指定的寄存器内容首先自动递减,然后该寄存器的值用于作为操作数的有效地址。
- 公式:
EA = [Ri-],Ri 自动递减 - 用途:
自动递增和自动递减模式通常用于堆栈操作。例如:Move --(SP), NEWITEM:将NEWITEM存储到栈顶,栈指针 SP 先递减后存储。Move ITEM, (SP)+:从栈顶取出 ITEM,然后栈指针 SP 增加,指向下一个项目。
精华:
- 自动增量模式和自动减量模式用于简化指针操作,特别是在数据结构如栈或数组的遍历过程中,能够自动调整指针的位置,减少显式的地址修改。
相对寻址模式(Relative Mode)
定义:
在相对寻址模式下,操作数的有效地址是通过使用程序计数器(PC)代替通用寄存器 Ri,再加上一个偏移量来确定的。公式:
EA = [PC] + X
其中,X 是一个带符号的数字。用途:
- 访问数据操作数。
- 在分支指令中指定目标地址。
示例:
- 分支操作:
Branch > 0 Loop
在这种情况下,分支目标地址可以通过从当前程序计数器值开始的偏移量来计算。
- 分支操作:
总结:
相对寻址模式常用于跳转指令中,通过程序计数器加上一个偏移量来计算目标地址,简化了控制流的计算和管理。
条件码(Condition Codes)
定义:
处理器可以维持关于运算结果的信息,以影响随后的条件分支操作。来源:
条件码根据算术运算、比较操作或数据搬移操作的结果来设置。条件码标志:
这些标志通常保存在状态寄存器中,主要包括:- N (负数标志):若结果为负,则设置为1,否则为0。
- Z (零标志):若结果为零,则设置为1,否则为0。
- V (溢出标志):若发生溢出,则设置为1,否则为0。
- C (进位标志):若发生进位,则设置为1,否则为0。
使用条件码的分支
CISC分支:
CISC风格的处理器会根据条件码标志来执行分支。通过判断条件码,程序可以执行不同的控制流操作。示例:
假设进行寄存器递减操作,若结果不为零,则清除N和Z标志。- 例如:检查条件
N + Z = 0,可以用分支指令Branch > 0 LOOP来实现。
- 例如:检查条件
其他条件:
- 比较条件:
<,=,≠,≤,≥等。 - 分支指令:
Branch_if_overflow:如果发生溢出,则跳转。Branch_if_carry:如果发生进位,则跳转。
- 比较条件:
Quiz
题目1: 在哪种寻址模式下,操作数实际上是直接包含在指令中的?
- A: 立即寻址模式 (Immediate mode)
- B: 直接寻址模式 (Direct mode)
- C: 寄存器寻址模式 (Register mode)
- D: 索引寻址模式 (Index mode)
答案: A. 立即寻址模式 (Immediate mode)
解释:
- 立即寻址模式:操作数直接包含在指令中,指令本身提供了操作数的值。
- 例如:
Add R4, R6, #200中的#200就是操作数,直接在指令中给出。
题目2: 在以下寻址模式中,哪个不属于RISC风格的计算机?
- A: 绝对寻址模式 (Absolute mode)
- B: 寄存器间接寻址模式 (Register indirect mode)
- C: 索引寻址模式 (Index mode)
- D: 间接寻址模式 (Indirect mode)
答案: D. 间接寻址模式 (Indirect mode)
解释:
- RISC(精简指令集计算机) 风格的计算机通常依赖于简单和快速的寻址模式,通常采用 寄存器寻址 或 立即寻址,而 间接寻址模式 在 RISC 计算机中较少使用。
- 间接寻址模式 需要通过内存来获取操作数的地址,这会增加额外的内存访问次数,降低效率,因此不常出现在 RISC 设计中。
题目3: 条件标志 Z 被设置为 1 以指示:
- A: 操作导致错误 (The operation has resulted in an error)
- B: 操作需要中断调用 (The operation requires an interrupt call)
- C: 结果为零 (The result is zero)
- D: 没有空闲寄存器 (There is no empty register available)
答案: C. 结果为零 (The result is zero)
解释:
- Z (Zero flag) 是条件码标志之一,它用于指示最近的运算结果是否为零。当 Z 标志被设置为 1 时,表示最近的操作结果为零。
RISC 和 CISC 风格
RISC(精简指令集计算机)特点:
- 简单的寻址模式:RISC 使用更简单、较少的寻址模式。
- 所有指令单词长度相同:RISC 中的每条指令都具有相同的长度,通常是一个字(word)。
- 较少的指令:指令集相对较小,通常只包含常见的操作。
- 算术/逻辑操作仅在寄存器上执行:数据处理通常只发生在寄存器中,内存操作则通过加载和存储指令来进行。
- 加载/存储架构用于数据传输:RISC 体系结构使用加载(load)和存储(store)指令来处理内存和寄存器之间的数据交换。
- 程序执行的指令数量较多:虽然每条指令较简单,但需要更多的指令来完成任务。
RISC 的优点:
- 简单的指令集使得设计更简单的硬件成为可能,有助于通过流水线技术(pipelining)提高执行速度。
CISC(复杂指令集计算机)特点:
- 更复杂的寻址模式:CISC 支持更多种类的寻址模式,允许更灵活的操作。
- 指令长度可变:CISC 中的指令可能跨越多个字节,有时会有变长的指令格式。
- 更多的指令:指令集较大,包含更多样化的指令。
- 算术/逻辑操作可在内存上执行:支持直接对内存中的数据进行算术和逻辑操作。
- 内存到内存的数据传输:CISC 支持内存与内存之间的直接数据传输。
- 每个程序执行的指令较少:由于指令更复杂,CISC 系统通常需要较少的指令来完成同样的任务。
CISC 的优点:
- 尽管硬件设计较为复杂,但在某些应用中仍可以设计出高效的处理器。
问题:以下哪项不是 RISC 风格的特点?
- A: 简单的寻址模式
- B: 所有指令都适合在一个单词中
- C: 指令集中的指令较少
- D: 算术和逻辑操作可以在内存操作数以及处理器寄存器中的操作数上执行
答案解析:
- A、B 和 C 都是 RISC 风格的特点。
- D 是 CISC 风格的特点,因为 RISC 风格通常只允许在寄存器内进行算术和逻辑操作,而不支持在内存操作数上执行这些操作。所以 D 不是 RISC 风格的特点。
正确答案:D
SUmmary
- 指令与指令顺序 (Instruction and Instruction
Sequencing)
- 研究指令的执行顺序和程序流控制,如何按照一定顺序执行指令,以及如何使用分支控制程序的跳转。
- 汇编语言符号 (Assembly Language Notation)
- 汇编语言中用于表示指令、操作数和操作码的符号。
- RISC 指令集 (RISC Instruction Sets)
- RISC 架构采用简化的指令集,指令通常固定长度,并且仅支持有限的寻址模式。
- 指令执行 (Instruction Execution)
- 包括直线顺序执行和分支执行,探讨程序控制流如何根据指令序列执行。
- 指令格式 (Instruction Formats)
- 指令的结构设计,如何将操作码、操作数等信息编码成机器指令。
- 指令表示 (Instruction Representation)
- 指令在机器中的表示方法,包括如何在计算机中存储和读取指令。
- 常见的指令地址字段格式 (Common Instruction Address Field
Formats)
- 不同地址字段格式的指令,如零地址、单地址、双地址、三地址指令等,解释它们的区别和应用。
- 操作码格式 (Opcode Format - Expanding Opcode)
- 操作码的格式与扩展,解释如何根据需要扩展操作码的位数以支持更多的操作。
- 寻址模式 (Addressing Modes)
- 寻址模式定义了如何指定操作数的存储位置,常见模式包括立即寻址、直接寻址、寄存器寻址等。
- 典型的 RISC 寻址模式 (Typical RISC Addressing
Modes)
- RISC 系统常用的寻址模式,通常包括寄存器寻址、立即寻址、堆栈寻址等。
- 堆栈与子程序 (Stack and Subroutine)
- 堆栈的使用和管理,如何利用堆栈支持子程序调用与返回。
- CISC 指令集 (CISC Instruction Sets)
- CISC 架构拥有更复杂的指令集,支持多种复杂的寻址模式和内存到内存的操作。
- 自动增量、自动减量和相对寻址 (Autoincrement, Autodecrement,
and Relative Mode)
- 自增、自减寻址模式和相对寻址模式的定义及应用。
- 条件码 (Condition Codes)
- 用于记录算术运算结果的状态,如负数、零、溢出、进位等条件码,以用于后续的分支控制。
- RISC 与 CISC 风格 (RISC vs. CISC Styles)
- 对比 RISC 与 CISC 架构的特点,RISC 强调简单的指令和更高效的执行,而 CISC 强调复杂的指令集和内存操作的直接支持。




